在互聯網誕生初期,數據庫主要的類型是關係型數據庫,這是一種採用了關係模型來組織數據的數據庫。這是在1970年由IBM研究員埃德加·弗蘭克·科德(E.F.Codd)博士首先提出的,在之後的幾十年中,關係模型的概念得到了充分的發展並逐漸成為主流數據庫結構的主流模型。簡單來說,關係模型指的就是二維表格模型,而一個關係型數據庫就是由二維表及其之間的聯繫所組成的一個數據組織。
隨著互聯網Web2.0網站的興起,傳統的關係數據庫在應對Web2.0網站,特別是超大規模和高並發的SNS類型的Web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而NoSQL的數據庫則由於其本身的特點得到了非常迅速的發展。NoSQL泛指非關係型的數據庫,它的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題。
以谷歌為例,谷歌公司大數據三篇著名論文(GFS,Bigtable,MapReduce)奠定了谷歌大數據的基礎,而谷歌的Pagerank算法實現了當時幾乎最先進的數據搜索算法。PageRank通過網絡浩瀚的超鏈接關係來確定一個頁面的等級。谷歌把從A頁面到B頁面的鏈接解釋為A頁面給B頁面投票,谷歌根據投票來源(甚至來源的來源,即鏈接到A頁面的頁面)和投票目標的等級來決定新的等級。簡單地說,一個高等級的頁面可以使其他低等級頁面的等級得到提升。而這個技術正是本章所指的數據第二階段,通過複雜的設計網絡和算法進行重新整理和歸納,將原本看似並無關聯的數據變為可以分級分類的高質量數據,讓大數據和複雜網絡模型成為可能。
但是構建在這之上的大數據,最大的問題就是無法解決信任問題。因為互聯網使得全球之間的互動越來越緊密,與之相伴而來的就是巨大的信任鴻溝。現有的主流數據庫技術架構都是私密且中心化的,在這個架構上是永遠無法解決價值轉移和互信的問題。所以區塊鏈技術將成為下一代數據庫架構,通過去中心化技術,將能夠在大數據的基礎上完成全球互信這個巨大的進步。
區塊鏈技術作為一種特定分佈式存取數據技術,通過網絡中多個參與計算的節點展開共同參與數據的計算和記錄,並且互相驗證其信息的有效性(防偽)。從這一點來看,區塊鏈技術也是一種特定的數據庫技術。這種數據庫將會實現梅蘭妮·斯旺(Melanie Swan)所說的第三種數據類型,即能夠獲得基於全網共識為基礎的數據可信性。目前,互聯網剛剛進入大數據時代,還處於初期階段。但是當進入到區塊鏈數據庫階段,將進入到真正的強信任背書的大數據時代。這裡面的所有數據都可以獲得堅不可摧的質量,任何人都沒有能力也沒有必要去質疑。
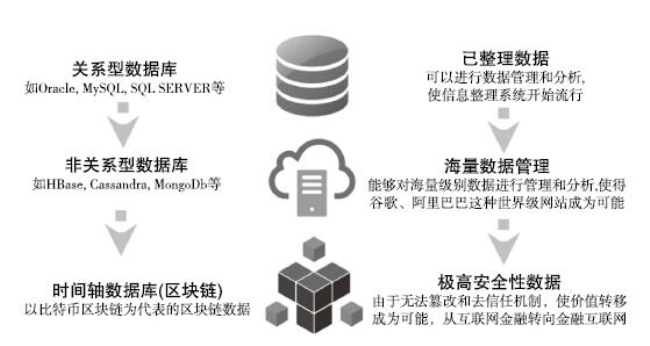
圖9.2 區塊鏈數據庫的優勢
從前面的發展我們可以注意到,數據的發展和馬斯洛需求層次理論有些接近,在實現了生存和使用的需求後,自然會朝著更高的需求進行發展。當然,安全僅僅是數據發展中的一個階段,而最終會朝著人工智能這個數據自我實現的需求發展。儘管我們還不能確定當數據能夠實現人工智能,甚至是數據自我智能時,數據庫會是怎樣的形態,也許未來的人工智能數據庫會變成像電影《復仇者聯盟》中的賈維斯和奧創這樣的形態吧。