夜幕降臨,大教堂的影子也漸漸變大。光線從教堂的彩色玻璃窗傾瀉而出,在大街上及遠處的建築上投射出複雜的公式。當你走近時,會聽到人們在裡面唱聖歌的聲音。唱的好像是拉丁語,又好像和數學有關,但你耳朵裡的巴別魚把它翻譯成英文:「轉動曲柄!轉動曲柄!」正當你邁進去時,聖歌漸漸轉化成聲聲滿意的「啊」以及「後面,後面」的呢喃。你穿過人群。聖壇上矗立著一塊巨大的石碑,上面刻著10英尺寬字母拼寫成的公式:
P (A∣B) = P (A) P (B∣A) / P (B)
當你不解地盯著這個公式看的時候,谷歌眼鏡起作用了,它閃了一下,說:「貝葉斯定理。」這時人群開始唱:「再多些數據!再多些數據!」大量的祭品正被無情地推向祭壇。突然,你意識到自己是祭品中的一個,但已經太晚了。當曲柄轉到你上方時,你喊著:「不!我不想變成數據點!放開我啊!」
你醒來時渾身冷汗。放在你大腿上的,是一本名為《終極算法》的書。甩掉噩夢之後,你接著從中斷的地方往下讀。
統治世界的定理
通往最優學習的路徑始於一個公式,這一點許多人都聽說過:貝葉斯定理。但在這裡,我們會以全新的眼光來看待這個公式,而且會意識到,它的力量要比你根據其日常用途猜測的要大得多。本質上,貝葉斯定理不僅僅是一個簡單的規則,當你收到新的論據時,它用來改變你對某個假設的信任度:如果論據和假設一致,假設成立的概率上升,反之則下降。例如,如果你查出艾滋病病毒呈陽性,你感染艾滋病的可能性上升。當你獲得許多條論據,例如,多重測試的結果時,事情就會變得更有意思。為了將所有論據結合起來,又免遭組合爆炸之苦,我們就得把猜想簡化。當我們同時考慮多個假設,例如,一個病人所有不同、可能的診斷時,事情也會變得更有意思。在合理時期內,根據病人的症狀來計算每種疾病發生的可能性需要很大的智慧。一旦知道如何來完成所有這些事情,我們就做好了學習貝葉斯方法的準備。對於貝葉斯學派來說,學習「僅僅是」貝葉斯定理的另外一個運用,將所有模型當作假設,將數據作為論據:隨著你看到的數據越來越多,有些模型會變得越來越有可能性,而有些則相反,直到理想的模型漸漸突出,成為最終的勝者。貝葉斯學派已經發明出非常靈活的模型。下面我們就開始來瞭解它們。
托馬斯·貝葉斯是一位18世紀的英國牧師,當時他並沒有發覺自己會成為新宗教的中心。你可能很想問怎麼會這樣,但注意到這也發生在耶穌身上後,就不會這樣問了:我們知道,基督教是由聖·保羅開創的,雖然耶穌把自己看作猶太教的頂峰。同樣,我們知道貝葉斯主義是由皮埃爾–西蒙·拉普拉斯創造的,他是比貝葉斯晚生50年的法國人。貝葉斯是第一個描述用新方法來考慮概率的牧師,但把那些想法變成定理,並以貝葉斯的名字來命名的人,卻是拉普拉斯。
拉普拉斯是史上最偉大的數學家之一,關於他,人們知道最多的可能就是他對於牛頓學說決定論的憧憬:
在任何給定的一瞬間,如果有某位智者能夠洞悉所有支配自然界的力和組成自然界的物體的相互位置,並且這位智者的智慧足以對這些數據進行分析,他就能用一個相同的公式來概括宇宙中最大的天體和最小的原子的運動。對這樣的智者來說,沒有什麼是不確定的,未來同過去一樣都歷歷在目。
這看起來有點諷刺的意味,因為拉普拉斯也是概率論的創始人之一,而他認為概率論僅僅是種可簡化為計算的常識。他對於概率的探索本質上是對於休謨問題的專注。例如,我們怎麼知道明天太陽會升起?太陽每天都會升起,今天也是,但沒有什麼能夠保證它會繼續升起。拉普拉斯的回答有兩個部分。第一部分是我們當今所謂的「無差別原則」,或者「理由不充分原則」。有一天我們醒來,比如這時正是時間的起點,對於拉普拉斯來說則是大概5000年前,經歷一個美妙的下午之後,我們看到太陽下山了。它還會出現嗎?我們還沒有看到過日出,所以也就沒有特殊理由認為它會或者不會再升起。因此我們應該考慮兩種情形出現的可能性相等,認為太陽還會再升起的可能性是一半。但是,拉普拉斯接著推斷,如果過去能指導未來的一切,因為太陽每天都會升起,這應該會讓我們更加堅信太陽會繼續升起。5000年過後,明天的太陽還會升起的概率應該接近1,但不完全是,因為我們不能完全肯定。由這個思維實驗,拉普拉斯導出他所謂的「接續法則」,該法則用於估算太陽升起n次後會再次升起的概率,表示為(n+1)/(n+2)。當n=0時,這個概率為1/2;隨著n增加,概率也會增加,當n接近無窮大時,概率接近1。
這個法則由一個更為通用的原則推導得出。假設你半夜在一個陌生的星球上醒來。雖然你能看到的只是繁星閃爍的天空,你有理由相信太陽會在某個時間點升起,因為多數星球會自傳並繞著自己的太陽轉。所以你估計相應的概率應該會大於1/2(比如說2/3)。我們將其稱為太陽會升起來的「先驗概率」,因為這發生在看到任何證據之前。「先驗概率」的基礎並不是數過去這個星球上太陽升起的次數,因為過去你沒有看到;它反映的是對於將要發生的事情,你優先相信的東西,這建立在你掌握的宇宙常識之上。但現在星星開始漸漸暗淡,所以你對於太陽會升起的信心越來越強,這建立於你在地球上生存的經歷之上。你的這種信心源自「後驗概率」,因為這個概率是在看到一些證據後得出的。天空開始漸漸變亮,後驗概率又變得更大了。最終,太陽銀色的大圓盤出現在地平線上方,而且可能正如《魯拜集》的開篇部分描寫的那樣,套中了「蘇丹的塔尖」。除非你產生幻覺,現在太陽是否會升起還不確定。
問題的關鍵是,隨著你看到的證據越來越多,後驗概率應該如何演變,答案就在貝葉斯定理裡面。我們可以根據因果關係來考慮這個問題。日出使星星漸漸褪去光芒,天空變亮,但後者更能證明黎明的到來,比如因為星星也有可能在深夜時分,因為霧氣籠罩而漸漸褪去光芒。所以看到天空變亮和看到星星褪去光芒相比,前者更能預示太陽升起的可能性。在數學符號中,我們說P(日出|天空漸漸發亮),即天空漸漸發亮時日出的條件概率,比P(日出|星星漸漸褪去光芒),即星星褪去光芒時日出的條件概率要大。根據貝葉斯定理,給定某原因時出現某結果的可能性越大,那麼出現該結果是該原因引起的概率也會越大:如果P(天空漸漸發亮|日出)比P(星星漸漸褪去光芒|日出)要大,也許是因為有些星球距離太陽足夠遠,那些星星在日出之後仍會發光,那麼P(日出|天空漸漸發亮)也比P(日出|星星漸漸褪去光芒)要大。
然而,情況並非完全如此。如果我們觀察一個即使沒有該原因也會發生的結果,那麼能肯定的是,該原因的證據力不足。貝葉斯通過以下句子概況了這一點:P(原因|結果)隨著P(結果),即結果的先驗概率(也就是在原因不明的情況下結果出現的概率)的下降而下降。最終,其他條件不變,一個原因是前驗的可能性越大,它該成為後驗的可能性就越大。綜上所述,貝葉斯定理認為:
P(原因|結果)=P(原因)×P(結果|原因)/ P(結果)
用A代替原因,用B代替結果,然後為了簡潔,把乘法符號刪掉,你就會得到大教堂上那個用10英尺寬的字母書寫的公式。
這僅僅是定理的一個表述,當然還不能作為證據。但讓人驚訝的是,證據十分簡單。我們可以用醫學診斷中的一個例子來闡明,也就是貝葉斯推理的「殺手級應用」之一。假設你是一位醫生,上個月已經為100名病人進行診斷。其中的14名病人患流感,20名發燒,11名既感冒也發燒。因此感冒的人群中有發燒的病人的條件概率為11/14。設立條件縮小了我們正在考慮的集合,在這個例子中,所有病人的範圍就縮小為患有流感的病人。在所有病人的集合中,發燒的概率是20/100;而在感冒病人的集合中,發燒的概率則是11/14。病人既發燒又感冒的概率,是患感冒病人的概率乘以發燒病人的概率:
P(感冒,發燒)=P(感冒)× P(發燒|感冒)=14/100 ×11/14=11/100
但我們可以倒過來計算:
P(感冒、發燒)=P(發燒)×P(感冒|發燒)
因此,因為它們都等於P(感冒、發燒),
P(發燒)×P(感冒|發燒)= P(感冒)×P(發燒|感冒)
兩邊都除以P(發燒),你會得到
P(感冒|發燒)= P(感冒)×P(發燒|感冒)/ P(發燒)
就是這樣!這就是貝葉斯定理,感冒是原因,發燒是結果。
事實證明,人類並不是很擅長貝葉斯推理,至少涉及文字推理的時候是這樣的。問題在於我們傾向於忽略原因的先驗概率。如果你的艾滋病病毒檢測呈陽性,而檢測的假陽性只有1%,你會覺得恐慌嗎?乍一看,這時你患有艾滋病的概率是99%。呀!可是讓我們冷靜一下,一步一步用貝葉斯定理來推導這個概率:
P(HIV|陽性)=P(HIV)×P(陽性|HIV)
P(HIV)是HIV在普通人群中的感染流行率,在美國這個概率約為0.3%。P(陽性)是化驗結果顯示你是否患有艾滋的概率,我們假設這個概率是1%。那麼P(HIV|陽性)=0.003×0.99/0.01=0.297。這和0.99有很大的差別!因為HIV在普通人群中較為少見。化驗結果為陽性,這樣你感染艾滋病的概率會增加兩個數量級,但這些概率還是低於50%。如果你的化驗結果為HIV陽性,接下來的準確做法是保持冷靜,然後做另外更加確切的檢查。檢查結果很有可能是你沒事。
貝葉斯定理之所以有用,是因為通常給定原因後,我們就會知道結果,但我們想知道的是已知結果,如何找出原因。例如,我們知道感冒病人發燒的概率,但真正想知道的是,發燒病人患感冒的概率是多少。貝葉斯定理讓我們由原因推出結果,又由結果知道原因,但其重要性遠非如此。對於貝葉斯定理的信仰者來說,這個偽裝起來的公式其實是機器學習中的F=ma等式,很多結論和應用都是在這個等式的基礎上得出的。而且無論終極算法是什麼,它肯定「僅僅」是貝葉斯定理的一個算法應用。我之所以給「僅僅」加了雙引號,是因為對於幾乎所有簡單的問題來說,在計算機上面應用貝葉斯定理非常困難,接下來,我們就會知道原因。
貝葉斯定理作為統計學和機器學習的基礎,受到計算難題和巨大爭論的困擾。你想知道原因也情有可原:這不就是我們之前在感冒的例子中看到的那樣,貝葉斯定理是由條件概率概念得出的直接結果嗎?的確,公式本身沒有什麼問題。爭議在於相信貝葉斯定理的人怎麼知道推導該定理的各個概率,以及那些概率的含義是什麼。對於多數統計學家來說,估算概率的唯一有效方法就是計算相應事件發生的頻率。例如,感冒的概率是0.2,因為被觀察的100名病人中,有20名發燒了。這是「頻率論」對於概率的解釋,統計學中佔據主導地位的學派就是由此來命名的。但請注意,在日出的例子以及拉普拉斯的無差別原則中,我們會做點不一樣的事:千方百計找到方法算出概率。到底有什麼正當的理由,能夠假設太陽升起的概率是1/2、2/3,或者別的呢?貝葉斯學派的回答是:概率並非頻率,而是一種主觀程度上的信任。因此,用概率來做什麼由你決定,而貝葉斯推理讓你做的事就是:通過新證據來修正你之前相信的東西,得到後來相信的東西(也被人們稱為「轉動貝葉斯手柄」)。貝葉斯學派對此觀點的忠實近乎虔誠,足以經得住200年的攻擊和計算。計算機已經強大到足以做貝葉斯推理,且在大數據的輔助下,它們開始佔據上風。
所有模型都是錯的,但有些卻有用
實際上,醫生不會僅憑發燒就斷定病人感冒了,他會考慮所有的症狀,包括病人是否咳嗽、喉嚨痛、流鼻涕、頭疼、發冷等。所以我們真正要算的是P(感冒|咳嗽、喉嚨痛、流鼻涕、頭疼、發冷……)。通過貝葉斯定理,我們知道這和P(咳嗽、喉嚨痛、流鼻涕、頭疼、發冷……|感冒)成正比。但現在,我們遇到一個問題:我們該如何估算這個概率?如果每個症狀就是一個布爾變量(你要麼有這個症狀,要麼沒有),醫生要考慮n個症狀,那麼病人就可能有2n種症狀的組合。假設我們有20種症狀以及1萬個病人的信息數據庫,那麼我們現在看到的僅僅是近100萬種可能組合中的一小部分。更糟的是,為了準確估算某個特定組合出現的概率,我們對該組合的觀察次數應至少為幾十次,這意味著數據庫需包含幾千萬個病人的信息。再另外增加10種症狀,我們需要病人的數量就會超過地球上的人口數。如果有100種症狀,即使我們能魔法般地得到數據,那麼世上所有的硬盤也沒有足夠的空間來存儲所有的概率。而且如果病人來到醫院,病人症狀的組合我們從未遇到過,那麼我們就不知該如何對其進行診斷。這時我們就與宿敵再次交鋒:組合爆炸問題。
因此,我們就照著生活中常發生的那樣做:妥協。我們做簡化的假設來減少概率的數量,這些概率的數量由我們估算而來,且我們可以掌控。一個很簡單且受人追捧的假設就是,在給定原因的情況下,所有的結果都相互獨立。例如,假如我們知道你感冒了,發燒並不會改變你也咳嗽的可能性。從數學的角度講,也就是說,P(發燒、咳嗽|感冒)僅相當於P(發燒|感冒)×P(咳嗽|感冒)。你瞧:這些概率中的每一個都可以通過少量次數的觀察得到。其實,在前文,我們就這樣得到過病人發燒的概率,且咳嗽和其他症狀的概率的算法也並無二致。那麼我們需要觀察的次數就不會隨著症狀數的增多而呈指數增長了,實際上,觀察次數不會再增長。
請注意:我們只是說你在感冒的前提下,發燒和咳嗽是相互獨立的,但並不是所有情況都如此。很明顯,如果我們不知道你有沒有感冒,那麼發燒和咳嗽則有很大關係,因為如果你已經發燒了,那你很有可能會咳嗽。P(發燒、咳嗽)不等於P(發燒)×P(咳嗽)。我們現在說的是,如果我們知道你感冒了,那麼知道你是否發燒,並不會讓我們更容易知道你是否會咳嗽。同樣,如果你不知道太陽要升起來了,而且你看到星星漸暗了,那麼你就更加肯定天空會變亮,但如果你知道太陽即將升起,那麼看到星星漸暗就沒有什麼影響了。
請再次注意:多虧貝葉斯定理,我們才掌握這個竅門。如果我們想直接估算P(感冒|發燒、咳嗽等),假如不利用定理先將其轉化成P(發燒、咳嗽等|感冒),那麼我們就還需要指數數量的概率,每個組合的症狀以及感冒或非感冒都有一個概率。
如果學習算法利用貝葉斯定理,且給定原因時,假定結果相互獨立,那麼該學習算法被稱為「樸素貝葉斯分類器」。因為這是一個很樸素的猜想。實際上,發燒會增加咳嗽的可能性,即使你知道自己感冒了,因為(舉個例子)發燒會讓你得重感冒的可能性增大。但機器學習就是會做錯誤猜想的技術,而它又能僥倖逃脫。正如統計學家喬治·博克斯說的一句很有名的話那樣:「所有的模型都是錯的,但有些卻有用。」雖然一個模型過於簡化,但你有足夠的數據用來估算那就比沒有數據的完美模型要好。令人詫異的是,有些模型錯誤百出,同時又很有用。經濟學家彌爾頓·弗裡德曼甚至在一篇很有影響力的文章中提出,最有說服力的理論往往受到最大程度的簡化,只要這些理論所做的預測是準確的,因為它們用最簡潔的方法解釋最複雜的問題。這對於我來說就像極遠處的一座橋,但它闡明:與愛因斯坦的名言相悖,至少可以這麼說,科學往往通過盡可能簡化事物來取得進步。
沒有人能肯定是誰發明了樸素貝葉斯算法。在1973年的一本模式識別教科書中,它被提到過,當時並未註明出處,但它真正流行起來是在20世紀90年代,那時研究人員驚喜地發現,它很多時候比許多更為複雜的學習算法還要準確。那時我還是一名研究生,而當我終於決定把樸素貝葉斯法納入我的實驗時,我震驚地發現自己很幸運,除了那個我運用到論文中的算法,它比所有我用來與之對比的算法都要有用,否則我可能也不會在這裡了。
樸素貝葉斯法如今應用得很廣泛。例如,它是許多垃圾郵件過濾器的基礎。而這一切開始於大衛·赫克曼(一位卓越的貝葉斯研究員,同時也是一名醫生),想到將垃圾郵件當作疾病,疾病的症狀就相當於郵件中的文字:「偉哥」是一種症狀,「免費」也是,但你最好朋友的姓可能會暗示這是一封合法郵件。那麼我們就可以利用樸素貝葉斯法來將郵件分為垃圾郵件和非垃圾郵件了,只要垃圾郵件製造者通過隨機選詞來生成郵件。當然,這是一個荒謬的假設:只有當句子沒有句法和內容時,它才正確。但那個夏天,邁赫蘭·沙哈和一位斯坦福大學的畢業生在微軟研究院實習時,曾對該假設進行過嘗試,且效果很好。當比爾·蓋茨問赫克曼怎會如此時,他指出為了識別垃圾郵件,你不必理解信息的細節,只要通過郵件包含的詞語來獲得郵件的主旨就可以了。
一個基本的搜索引擎也會利用與樸素貝葉斯法極相似的算法來決定顯示哪些頁面來回應你的搜索。主要的區別在於:它會預測相關或非相關,而不是垃圾郵件或非垃圾郵件。運用樸素貝葉斯法來解決預測問題的例子幾乎數不勝數。彼得·諾爾維格(谷歌的研究主任)一度告訴我,這是谷歌應用最為廣泛的算法,谷歌的機器學習在每個角落都利用了該算法的功能。為什麼樸素貝葉斯法會在谷歌員工中流行起來?這個問題不難回答。除了驚人的準確度,它的測量能力也很強。學習樸素貝葉斯分類器的原理,也僅相當於數出每個屬性與每個類別出現的次數,花的時間不比從硬盤讀取數據的時間長。
可以半開玩笑地說,你甚至可以比谷歌員工更大範圍地利用樸素貝葉斯法:對整個宇宙進行模擬。的確,如果你相信全能的上帝,那麼你可以將宇宙模擬成一個巨大的樸素貝葉斯法分佈點,這裡發生的每件事都是在上帝的意願下獨立發生的。當然,值得注意的是,我們不知道上帝在想什麼,但在第八章我們會分析,如何在即使不知道例子類別的情況下,掌握樸素貝葉斯模型。
起初看起來可能不是這樣,但樸素貝葉斯法與感知器算法密切相關。感知器增加權值,而樸素貝葉斯法則增加概率,但如果你選中一種算法,後者會轉化成前者。兩者都可以概括成「如果……那麼……」的簡單規則,這樣每個先例都會多多少少體現在結果中,而不是在結果中「全有或全無」。這僅僅是暗指主算法的學習算法中關聯較為深入的例子。你也許並沒有有意識地去瞭解貝葉斯定理(那麼,你現在意識到了),但在某種程度上,你大腦中數百億神經元中的每一個都是貝葉斯定理的微小實例。
在看新聞時,樸素貝葉斯法是學習算法可以利用的良好概念模型:它可以捕獲輸入與輸出之間兩兩相關的關係,這對於理解將學習算法引用到新事件中很有必要。但是機器學習也不僅僅和兩兩相關關係有關,當然,正如大腦不僅僅包含一個神經元一樣。當我們尋找更為複雜的模型時,真正的行動才剛剛開始。
從《尤金·奧涅金》到Siri
1913年第一次世界大戰前夕,俄國數學家安德烈·馬爾可夫發表了一篇文章,將所有事情的概率運用到詩歌當中。詩中,他模仿俄國文學的經典:普希金的《尤金·奧涅金》,運用了當今我們所說的「馬爾可夫鏈」。他沒有假定每個字母都是隨機產生的,與剩下的毫無關聯,而是最低限度引入了順序結構:他讓每個字母出現的概率由在它之前、與它緊接的字母來決定。他表示,舉個例子,元音和輔音常常會交替出現,所以如果你看到一個輔音,那麼下一個字母(忽略發音和空格)很有可能就是元音,但如果字母之間互相獨立,出現元音的可能性就不會那麼大。這可能看起來微不足道,但在計算機發明出來之前的年代,這需要花費數小時來數文字,而馬爾可夫的觀點在當時則很新穎。如果元音i是一個布爾型變量,《尤金·奧涅金》的第i個字母是元音,則該變量為真,如果它是一個輔音則為假,那麼我們用圖6–1這樣的連鎖圖來表示馬爾可夫模型,兩個節點之間的箭頭表示相應變量之間的直接依賴關係:

圖6–1
馬爾可夫假設(假設錯誤但有用)文中每個位置的概率都是一樣的。因此我們只需估算三個概率:P(元音1=真),P(元音i+1=真|元音i=真),且P(元音i+1=真|元音i=假〔因為概率相加等於1,由此我們可以馬上得出P(元音1=假)等〕。與樸素貝葉斯法一樣,我們可以隨心所欲擁有許多變量,而不用估算可能會抵達上限的概率的數量,但現在變量之間實際上會相互依賴。
如果我們測量的不僅僅是元音對輔音的概率,還有字母順序遵循字母表順序的概率,利用與《尤金·奧涅金》一樣的統計數據,我們可以很愉快地生成新的文本:選擇第一個字母,然後在第一個字母的基礎上選擇第二個字母,以此類推。當然結果是一堆沒有意義的數據,但如果我們讓每個字母都依照之前的幾個字母而不止一個字母,這個過程就開始聽起來更像一個酒鬼的瘋話,雖然從整體上看沒有意義,但從局部上看卻很連貫。雖然這還不足以通過圖靈測試,但像這樣的模型是機器翻譯系統的關鍵組成部分,比如谷歌翻譯可以讓你看到整版的英文頁面(或者幾乎整版),不管原頁面的語言是什麼。
源於谷歌的頁面排名,本身就是一條馬爾可夫鏈。拉裡·佩奇認為,含有許多鏈接的頁面,可能會比只含幾個的要重要,而且來自重要頁面的鏈接本身也更有價值。這樣就形成了一種無限倒退,但我們可以利用馬爾可夫鏈來掌控這種倒退。想像一下,一個頁面搜索用戶通過隨機點擊鏈接來從這個頁面跳到另外一個頁面:這時馬爾可夫鏈的狀態就不是文字而是頁面了,這樣問題就變得更為複雜,但數學原理是一樣的。那麼每個頁面的得分就是搜索用戶花在該頁面上的時間,或者等於他徘徊很久後停留在該頁面上的概率。
馬爾可夫鏈無處不在,而且是人們研究最多的數學話題,但它仍是受到很大限制的概率模型。我們可以用圖6–2中的模型來進一步探討這個問題。
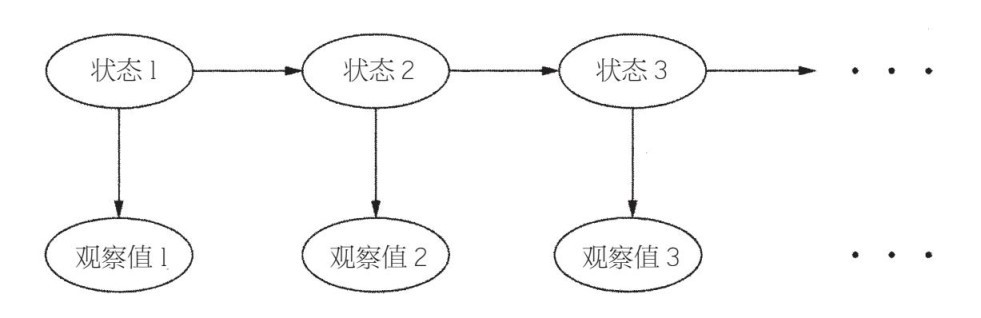
圖6–2
與之前一樣,這些狀態組成一條馬爾可夫鏈,但我們看不到它們,得從觀察中將它們推導出來。人們稱其為隱藏的馬爾可夫模型,或者簡稱為HMM(有點誤導人,因為被隱藏的是狀態,而不是模型)。HMM和Siri一樣,處於語音識別系統的中心。在語音識別過程中,隱藏的狀態是書面形式的單詞,而觀察值則是對Siri說的聲音,而目標則是從聲音中推斷出單詞。模型有兩個組成部分:給定當前單詞的情況下,下一個單詞出現的概率和在馬爾可夫鏈中的一樣;在單詞被說出來的情況下,聽到各種聲音的概率(到底如何進行推導,這是一個有趣的問題,下面我們會來討論這個問題)。
除了Siri,你每次用手機來通話時都會用到一個HMM。這是因為你的詞語在空氣中以位流的形式發送,而數位在發送過程中會受到損壞。這個HMM接著會從接收到的數位中(觀察值)找到預期的那個(隱藏狀態),這是HMM應該能做得到的,只要受損的數位不是很多。
HMM還是計算生物學家最為喜愛的工具。一個蛋白質分子是一個氨基酸序列,而DNA則是一個鹼基序列。舉個例子,如果我們想預測一個蛋白質分子怎樣才能形成三維形狀,我們可以把氨基酸當作觀察值,把每個點的褶皺類型當作隱藏狀態。同樣,我們可以用一個HMM來確定DNA中基因開始轉錄的地點,還可以確定其他許多屬性。
如果狀態和觀察值都是連續而非離散變量,那麼HMM就變成人們熟知的卡爾曼濾波器。經濟學家利用卡爾曼濾波器來從數量的時間序列中消除冗余,比如GDP(國內生產總值)、通貨膨脹、失業率。「真正的」GDP值屬於隱藏的狀態;在每一個時間點上,真值應該與觀察值相似,同時也與之前的真值相似,因為經濟很少會突然跳躍式增長。卡爾曼濾波器會交替使用這兩者,同時會生成流暢的曲線,仍與觀察值一致。當導彈巡航到目的地時,就是卡爾曼濾波器使它保持在軌道上。沒有卡爾曼濾波器,人類就無法登上月球。
所有東西都有關聯,但不是直接關聯
HMM有助於模擬所有種類的序列,但它們遠遠不如符號學派的「如果……那麼……」規則靈活,在這個規則當中,任何事都可以以前提的形式出現,而在任意下游規則中,一條規則的結果可以反過來當作前提。然而,如果我們允許如此隨意的結構在實踐中存在,那麼需要掌握的概率數量將會呈爆發式增長。很長一段時間,沒有人知道該如何打破這個循環,而研究者們只能求助於特別方案,比如將置信度估算與規則掛鉤,並以某種方式將它們聯合起來。如果A以0.8的置信度暗指B,而B以0.7的置信度暗指C,那麼也許A暗指C的置信度則為0.8×0.7。
這些方案的問題在於,它們可能會嚴重出錯。我可以根據兩個合情合理的規則——如果滅火噴水系統打開了,那麼玻璃就會濕;如果玻璃濕了,那麼下雨了——推導出一條荒謬的規則:如果滅火噴水系統打開了,那麼下雨了。一個潛藏得更深的問題是,有了置信度評級規則,我們容易重複計算證據。假設你在讀《紐約時報》,講的是外星人已經登陸地球。這一天不是4月1日,可能這是一個玩笑。但是現在你在《華爾街日報》《今日美國》《華盛頓郵報》看到一樣的標題。你開始感到慌張,就像奧森·威爾斯聲名狼藉的廣播劇《世界大戰》的聽眾一樣,沒有意識到這只是戲劇化的描寫。但是,如果你查看細節,會發現這四家報社都從美聯社那裡得到這個新聞標題,你又返回去懷疑這是一個玩笑,而這次開玩笑的是一位美聯社的記者。規則系統無法解決這個問題,樸素貝葉斯法也一樣。如果它標出諸如「由《紐約時報》報道」的字樣,預示新聞事件是真實的,那麼它能做的也只是加上「由美聯社報道」的字樣,這樣只會讓事情變得更糟糕。
20世紀80年代終於有了突破。朱迪亞·珀爾(加州大學洛杉磯分校的一名計算機科學教授)發明了一種新的表示方法:貝葉斯網絡。珀爾是世界上最為卓著的計算機科學家之一,他的方法在機器學習、人工智能,以及其他許多領域迅速傳播。2012年,他獲得圖靈獎,這是計算機科學領域的諾貝爾獎。
珀爾意識到,擁有一個隨機變量之間複雜的依賴關係網絡也沒什麼,只要每個變量僅僅直接依賴於其他幾個變量。我們可以如之前看到的馬爾可夫鏈和HMM那樣,用一幅圖來表示這些依賴關係,除了現在該圖可以是任意結構(只要箭頭不會形成閉環)。珀爾最喜歡的例子之一就是防盜報警器。當竊賊企圖闖入時,你房子的報警器應該會響起來,但它也可能會因為地震而響起(在洛杉磯,珀爾居住的地方,地震和盜竊案發生的頻率一樣)。如果你此時工作到很晚,而你的鄰居鮑勃打電話給跟說他聽到你家的報警器響了,而你的鄰居克萊爾卻沒打給你,你應該報警嗎?圖6–3表明了這種依賴關係。
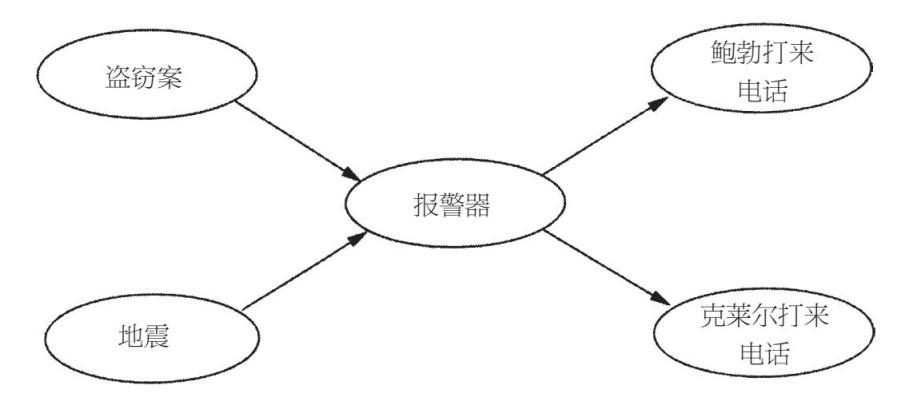
圖6–3
如果圖中有一個箭頭從一個節點指到另外一個節點,我們說第一個節點是第二個節點的父節點。那麼「報警器」的父節點就是「盜竊案」和「地震」,而「報警器」是「鮑勃打來電話」和「克萊爾打來電話」的唯一父節點。貝葉斯網絡就是像這樣的依賴關係圖,附帶一張包含每個變量的表格,給出變量父節點的每個值的組合概率。對於「盜竊案」和「地震」,我們只需每個一個概率,因為它們沒有父節點。對於「報警器」我們需要四個概率:如果盜竊案和地震都不發生,報警器響起的概率;如果盜竊案發生,地震未發生,報警器響起的概率等。對於「鮑勃打來電話」,我們需要兩個概率(考慮報警器和未考慮報警器),克萊爾的情況也一樣。
以下是問題的關鍵點:鮑勃依據「盜竊案」和「地震」來打電話,但只能通過「報警器」來獲取信息。考慮到「報警器」時,鮑勃的電話才會條件地獨立於「盜竊案」和「地震」之外,克萊爾的情況也一樣。如果報警器未響起,你的鄰居睡得很香,而竊賊也沒有驚擾別人。同樣,考慮到「報警器」,鮑勃和克萊爾相互獨立。沒有這個獨立結構,你需要掌握32個25概率,每個概率對應5個變量的可能狀態(或者31個概率,如果你講究細節,因為最後一個可能是隱含概率)。有了條件獨立性,你需要的只是1+1+4+2+2=10,可以少算68%的概率。這僅僅是小例子的情況,如果有數百或者數千個變量,省力的程度可能達到100%。
據生物學家巴裡·康芒納的觀點,生態學的第一定律就是所有生命都與其他生命相互關聯。這個說法可能正確,但也會使人們無法理解這個世界,如果不是多虧條件獨立性:每個生命都相互關聯,但只是間接關聯。為了對我產生影響,1英里之外發生的事情,即使通過光傳播,也得先影響我周圍的環境。可以打趣說,空間是所有事情沒有都發生在你身上的原因。換句話說,空間結構是條件獨立性的一個實例。
在盜竊案的例子中,32個概率的完整表格不會明確表示出來,但通過較小表格和圖形結構的集中,它會被隱含地表示出來。為了獲得P(盜竊案、地震、報警器、鮑勃打來電話、克萊爾打來電話),我要做的就是把以下概率相乘:P(盜竊案)、P(地震)、P(報警器∣盜竊案、地震)、P(鮑勃打來電話∣報警器)、P(克萊爾打來電話∣報警器)。在任意貝葉斯網絡中也是同樣的道理:為了獲得完整狀態的概率,只需將單個變量表格中相應行上的概率相乘。因此,只要條件獨立性有效,轉換到更加簡潔的表示方法不會導致信息丟失。這樣我們就可以很容易算出極端非尋常狀態的概率,包括之前未觀察到的狀態。貝葉斯網絡揭穿這樣一個常識性錯誤:機器學習無法預測鮮有的時間,或者納西姆·塔勒布口中的「黑天鵝」。
回想一下,我們可以看到樸素貝葉斯法、馬爾可夫鏈、HMM都是貝葉斯網絡的特殊例子。樸素貝葉斯法的結構如圖6–4所示。
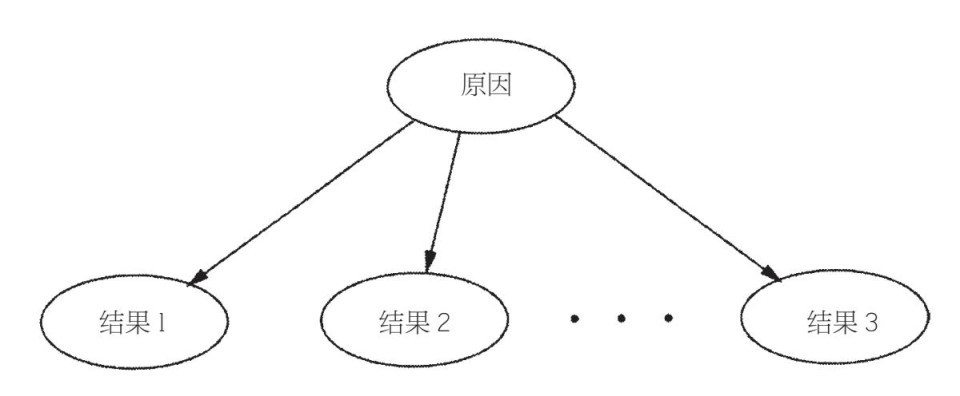
圖6–4
馬爾可夫鏈隱含這樣的猜想:考慮到現在,未來會有條件地獨立於過去。此外,HMM假設每個觀察值只依賴於對應的狀態。貝葉斯網絡對貝葉斯學派來說,就像邏輯與符號學者的關係:一種通用語,可以讓我們很好地對各式各樣的情形進行編碼,然後設計出與這些情形相一致的算法。
我們可以把貝葉斯網絡想成「生成模型」,即從概率的角度,形成世界狀態的方法:首先要決定盜竊案或地震是否會發生,然後在此基礎上決定報警器是否會響起,再次在此基礎上決定鮑勃和克萊爾是否會打電話。貝葉斯網絡講述這樣的故事:A發生了,接著它導致B的發生;同時,C也發生了,而B和C共同引起D的發生。為了計算特定事件的概率,我們只需將與之相關事件的概率相乘即可。
貝葉斯網絡最激動人心的應用之一,就是模擬基因在活細胞中如何相互管制。人們已經花費數十億美元來找到單個基因和特殊疾病的兩兩相關關係,但產出卻低得讓人失望。回想一下,這並不奇怪:細胞的活動是基因與環境複雜的相互作用的結果,而單個基因的預測能力有限。但有了貝葉斯網絡,我們可以揭開這些相互關係,只要我們有必要的數據,而隨著DNA微陣列技術的普及,我們越來越有希望能做到。
開闢機器學習在垃圾郵件的應用之後,大衛·赫克曼開始轉向將貝葉斯應用於抵抗艾滋病的鬥爭中。艾滋病病毒是很強的對手,因為它可以迅速變異,這樣所有疫苗或者藥物長時間抑制艾滋病病毒就變得困難。赫克曼注意到,這是一個和貓捉老鼠一樣的遊戲,垃圾郵件過濾器和垃圾郵件玩耍。他決定將自己學習的一個經驗付諸實踐:攻擊最弱的鏈接。在垃圾郵件的例子中,弱鏈接包括為了收到客戶的款項而必須使用的網址。在艾滋病的例子中,它們就是病毒蛋白質的微小區域,不傷害病毒就無法改變這些區域。如果他可以對免疫系統進行訓練,使其識別這些區域,然後攻擊表現這些區域的細胞,他可能只有一種艾滋病疫苗。赫克曼和同事利用貝葉斯網絡來幫助識別易受傷區域,並研發出一個疫苗交付機制,用來教免疫系統只攻擊那些區域。這些交付機制在老鼠身上起作用了,而且現在人們已經在準備臨床試驗。
這樣的事情經常發生:即使我們將所有條件獨立性都考慮進來,貝葉斯網絡中的一些節點仍有太多的父節點。有些網絡佈滿箭頭,這樣當我們打印這些網絡圖時,紙面會變成黑色(物理學家馬克·紐曼稱之為「荒謬圖」)。醫生需要同時診斷病人可能患的病,而不止一種,而且每種疾病是許多不同症狀的根源。除了感冒,發燒可能由任意數量的條件引起,但是考慮到條件的每個可能的組合,嘗試預測其概率幾無希望。其實還有一線希望,不需要這樣的表格:為每個狀態的起因詳細說明每個節點的條件概率,我們可以對較簡單的分佈進行學習。最受青睞的選擇是邏輯OR運算(Logical OR operation)的一個概率版本:任何原因都可以獨自引起發燒,但每個原因都會有一個特定、無法引起發燒的概率,即使通常情況下該原因引起發燒的理由充分。赫克曼和其他人已經對貝葉斯網絡進行學習,通過這種方法來診斷數百種傳染病。谷歌在其AdSense系統中利用這種類型的龐大貝葉斯網絡,用於自動選擇廣告放入網頁中。該網絡將100萬的滿足變量相互關聯起來,同時還通過3億個箭頭與1200萬的詞語和詞組相關聯,這些詞語和詞組都是從1000億個文本片段和搜索詞條中掌握的。
說點輕鬆的,微軟的Xbox Live遊戲用貝葉斯網絡來對選手進行排名,並對技術水平相似的選手進行配對。這款遊戲的結果就是可以知道對手技術水平的一個概率函數,而且利用貝葉斯定理,我們可以從選手的遊戲結果推斷選手的技術水平。
推理問題
遺憾的是,推理問題是一個巨大的障礙。僅僅因為貝葉斯讓我們簡潔地表達概率分佈,這並不意味著我們也可以利用它進行有效推理。假設你想計算P(盜竊案∣鮑勃打電話,而克萊爾沒有)。利用貝葉斯定理,你知道這僅僅是P(盜竊案)P(鮑勃打電話,而克萊爾沒有∣盜竊案)/P(鮑勃打電話,而克萊爾沒有),或者相當於P(盜竊案,鮑勃打電話,而克萊爾沒有)/P(鮑勃打電話,而克萊爾沒有)。如果有包含所有狀態的概率的完整表格,你可以獲得這兩個概率,方法就是把表格中對應行的值加起來。例如,P(鮑勃打電話,而克萊爾沒有)是在所有包含鮑勃打電話,而克萊爾沒有的概率的行中,把這些概率值加起來,但是貝葉斯網絡不會給你完整的表格。你總可以通過單個表格來構建這樣的表格,但這需要很多時間和空間。我們真正需要的是計算P(盜竊案∣鮑勃打電話,而克萊爾沒有),而不用建立完整的表格。簡單地說,那就是貝葉斯網絡中的推理問題。
在許多例子中,我們可以做到這一點,並避免指數性暴增。假設夜深人靜時你正帶領排成縱隊的一個排,穿過敵人的領地,而你想確認所有士兵仍在跟著你。你可以停下,自己數人數,但那樣做會浪費太多時間。一個更聰明的辦法就是只問排在你後面的第一個兵:「你後面有幾個兵?」每個士兵都會問自己後面的士兵同一個問題,知道最後一個士兵回答「一個也沒有。」倒數第二個士兵現在可以說「一個」,以此類推,直到回到第一個士兵,每個士兵都會在後面士兵所報數的基礎上加一。現在你知道有多少兵還跟著你,你甚至都不用停下來。
Siri用同樣的想法來計算你剛才說的概率,通過它從麥克風中聽到的聲音來進行「報警」。把「Call the police」(報警)想成一排單詞,正以縱隊形式在頁面上行走,「police」想知道它的概率,但要做到這一點,它需要知道「the」的概率;「the」回過頭要知道「call」的概率。所以「call」計算它的概率,然後將其傳遞給「the」,「the」重複步驟並將概率傳遞給「police」。現在「police」知道它的概率了,這個概率受到句子中每個詞語的適當影響,但我們絕不必建立8個概率的完整表格(第一個單詞是否為「call」,第二個是否為「the」,第三個是否為「police」)。實際上,Siri考慮在每個位置中出現的所有單詞,而不僅僅是第一個單詞是否為「call」等,但算法是一樣的。也許Siri認為,在聲音的基礎上,第一個單詞不是「call」就是「tell」,第二個不是「the」就是「her」,第三個不是「police」就是「please」。個別地,也許最有可能的單詞是「call」、「the」和「please」。但那樣會變成一句沒有意義的話「Call the please」,所以要考慮其他單詞,Siri得出結論,認為句子就是「Call the police」。它會打電話,幸運的是警察及時趕到你家並抓住小偷。
如果圖是一棵樹而不是一條鏈,那麼同樣的想法還會奏效。如果你領導的是整支軍隊而不僅僅是一個排,你可以問每個連長,他們身後有多少士兵,然後把他們的回答相加。反過來,每個連長會問他的每個排長,以此類推。但如果圖形形成環狀,你就會遇到麻煩。如果有一個聯絡官員,他同時是兩個排的成員,他會數兩次數。實際上,他身後的每個人都會數兩次。這就是「外星人登陸」情形中發生的問題,舉個例子,如果你想計算恐慌的概率,如圖6–5所示。
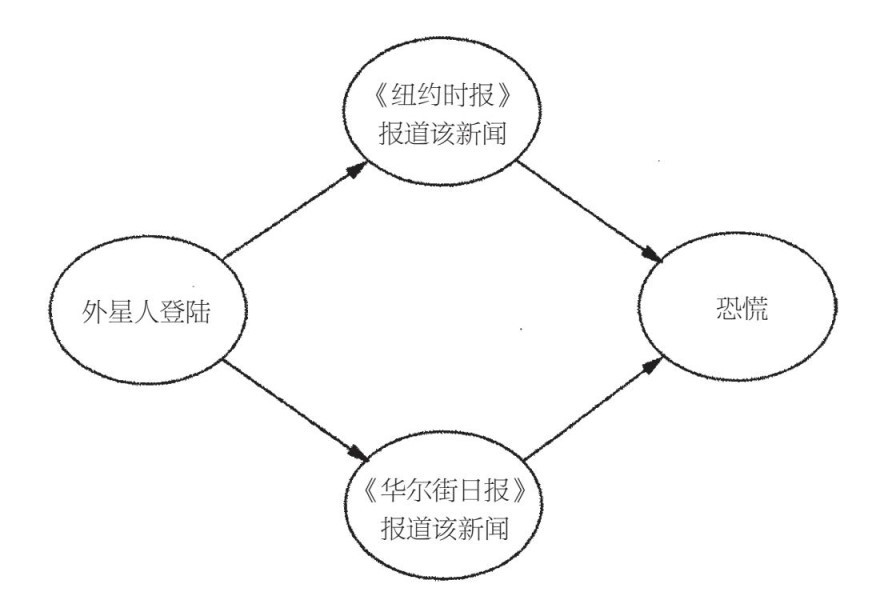
圖6–5
有一個辦法就是將「《紐約時報》報道該新聞」與「《華爾街日報》報道該新聞」結合起來,變成一個擁有4個值的單個特大變量:如果它們都報道了,那就是「是是」;如果《紐約時報》報道外星人登陸,而《華爾街日報》沒有,那就是「是否」;等等。這樣圖形就會變成一條含三個變量的鏈子,一切順利。然而,每次你加入新來源時,特大變量的值的數量會翻倍。如果你有50而不是2個新來源,特大變量會有250個值。所以這種方法只能幫你幫到這裡,而更有效的方法還未被人發現。
這個問題比表面看起來的還要糟糕,因為貝葉斯網絡實際上有「隱形的」箭頭伴隨著看得見的箭頭。「盜竊案」和「地震」是相互獨立的先驗條件,但報警器響起會使兩者糾纏在一起:報警器讓你懷疑有盜竊,但如果現在聽廣播說有地震,你會假定那是讓報警器響起的原因。地震已經「通過解釋消除」報警器響起的疑慮,這樣盜竊就不太可能會發生,因此兩者又相互依賴了。在貝葉斯網絡中,所有變量的根源都以這種方式相互獨立,而這反過來引入進一步的依賴關係,這就使得最後的圖往往比最初的圖要更加密集。
推理的關鍵問題是你能否使填好的圖「看起來像一棵樹」,而不讓樹幹變得太密。如果枝幹上的特大變量包含過多的可能值,這棵樹會不受限制地生長,直到它覆蓋整個星球,像《小王子》中的猴麵包樹一樣。在生命之樹中,每個物種都是一個分枝,但每個枝幹內部是一個圖,每個生物都有一對父母,各有一對祖父母、外祖父母,以及若干個後代等。枝幹的「厚度」是物種數量的大小。當枝幹過於茂密時,我們的唯一選擇就是求助於近似推理。
有一個方法,珀爾在關於貝葉斯網絡的書中,將其當作練習,也就是假裝圖形沒有閉環,並來來回回傳播概率,直到這些概率集中於一點。這被人們稱為「環路信念傳播」(loopy belief propagation),因為它在含有閉環的圖形中能起作用,也因為這是一個瘋狂的想法。讓人驚訝的是,在許多例子中,它能很好地起作用。例如,這對於無線通信來說,是最先進的方法,隨機變量在信息中被當作數位,以靈活的辦法被編碼起來。環路信念傳播也可以收斂變成錯誤的答案,或者永遠處於振蕩狀態。還有另一個辦法,它起源於物理學,但被引入機器學習,還被邁克爾·喬丹和其他人大大擴充過:就是利用易於處理的分配來對難以處理的分配進行粗略估計,然後優化前者的參數,使其盡可能地與後者接近。
然而,最受人青睞的選擇就是借酒澆愁,喝得酩酊大醉,然後整夜都在跌跌撞撞。該選擇的技術術語為「馬爾可夫鏈蒙特卡洛理論」(Markov chain Monte Carlo,MCMC):有「蒙特卡洛」這個部分,是因為這個方法涉及機遇,比如到同名的賭場去,有「馬爾可夫鏈」部分,是因為它涉及採取一系列措施,每個措施只能依賴於前一個措施。MCMC中的思想就是隨便走走,就像眾所周知的醉漢那樣,以這樣的方式從網絡的這個狀態跳到另一個狀態。這樣長期下來,每個狀態受訪的次數就與它的概率成正比。比如,接下來我們可以估算盜竊案的概率為我們訪問某個狀態的時間段,在這個狀態中有一起盜竊案。一條「守規矩的」馬爾可夫鏈會收斂到穩定分佈中,所以過一會兒它總會給出大致一樣的答案。例如,當你洗一副撲克牌時,過一會兒,所有牌的順序都會近似,無論最初的順序是什麼。所以你知道如果有n種可能的順序,每種順序的概率就是1/n。MCMC的秘訣就在於設計一條馬爾可夫鏈,收斂於我們貝葉斯網絡的分佈中。有一個簡單的選擇,就是重複循環通過所有變量,考慮其附近的狀態,根據其條件概率對每個變量進行取樣。人們在談論MCMC時,往往把它當作一種模擬,但它其實不是:馬爾可夫鏈不會模仿任何真實的程序,我們將其創造出來,目的是為了從貝葉斯網絡中有效生成樣本,因為貝葉斯網絡本身就不是序變模式。
MCMC的起源可以追溯到曼哈頓計劃,那時物理學家們需要估算中子與原子相撞的概率,並引發連鎖反應。但近10年來,這引發了一場革命,常常使人們認為MCMC是有史以來最重要的算法之一。MCMC不僅有助於計算概率,也有助於求任何函數的積分。沒有它,科學家們只能受限於那些用分析方法來求積分的函數,或者受限於那些良性的低維積分,這些積分可以近似看作一系列梯形。有了MCMC,科學家們就可以自由構建複雜的模型,直到計算機會挑起重擔。貝葉斯學派,舉個例子,可能要感激MCMC,因為MCMC和其他東西比,更能為他們的方法提高人氣。
不好的一面在於,MCMC的收斂速度往往慢得讓人難以忍受,或者在未完成收斂時欺騙你已經完成收斂。真正的概率分配通常非常懸殊,微小概率的大片「荒地」會突然插入「珠穆朗瑪峰」。接下來,馬爾可夫鏈會收斂到最近的頂峰,然後停留在那裡,得出偏差很大的概率估算值。這就像醉鬼跟隨酒的香氣來到最近的酒館,然後整夜待在那裡,而不是我們想讓他做的那樣,到城市裡遊蕩。另一方面,如果我們不用馬爾可夫鏈而是只生成獨立的樣本,和較簡單的蒙特卡落法一樣,沒有任何味道指引我們,而且甚至可能都找不到那個第一家酒館。這就像往城市的地圖上射飛鏢,希望飛鏢能恰好落在酒館上。
貝葉斯網絡中的推理不僅限於計算概率,它也包括為證據找到最可信的解釋方法,最能解釋症狀的疾病或者最能解釋Siri聽到的聲音的詞語。這和只是在每步挑最合適的詞語不一樣,因為在考慮聲音的情況下,單個出現可能性大的詞語,一起出現時可能性就不那麼大了,在「Call the please」的例子中就是如此。可是,相同種類的算法也可以對這個任務起效(實際上,多數語音識別器會用到它們)。最重要的是,推理包括做最佳決定,引導這些決定的,不僅僅是不同結果的概率,還有相應的成本(或者使用這些技術術語的實用工具)。忽略你老闆的郵件,安排你明天該做的事情,這比看到垃圾郵件付出的代價還要大,所以很多時候最好允許郵件通過,即使有時候它很有可能是垃圾郵件。
無人駕駛車輛和其他機器人是實踐中概率推理的最好例子。隨著車轉悠起來,它同時會構建行駛領域的地圖,越來越肯定地找到它在地圖上的方位。根據最近的一項調查,倫敦的出租車司機大腦靠後的海馬區域比常人要大,這是一個涉及記憶和地圖形成的大腦區域,因為他們要掌握城市的佈局。也許他們利用的是相似的概率推理算法,這和人類的情況就不一樣,飲酒似乎並不能幫上什麼忙。
掌握貝葉斯學派的方法
既然我們(多多少少)知道了如何解決推理難題,就可以從數據中掌握貝葉斯網絡了,因為對於貝葉斯學派來說,學習只是另一種形式的概率推理。你需要做的只是運用貝葉斯定理,把假設當作可能的原因,把數據當作觀察到的效果:
P(假設∣數據)=P(假設)×P(數據∣假設)/P(數據)
假設可以和整個貝葉斯網絡一樣複雜,或者和硬幣正面朝上的概率一樣簡單。在後一個例子中,數據僅僅是一系列拋硬幣行為的結果。例如,如果我們拋100次硬幣,有70次正面朝上,頻率論者會估算正面朝上的概率為0.7。根據所謂的「極大似然法」(maximum likelihood principle),這是有道理的:在所有正面朝上的可能概率中,0.7是在拋100次,有70次正面朝上的情況下最有可能的概率。假設成立的可能性是P(數據∣假設),而該法則稱,我們應該選擇那個能將該概率最大化的假設。即便如此,貝葉斯學派做事更加仔細。他們指出,我們從來無法肯定哪個假設是真的,所以我們不只是挑一個假設,比如硬幣正面朝上的概率是0.7;相反,應該計算每個可能假設的後驗概率,然後在做預測時容納所有假設。所有假設的概率之和必須等於1,那麼如果某個假設的概率增大,另一個則變小。實際上,對於貝葉斯學派來說,沒有所謂的真相。你有一個優先於假設的分佈,在見到數據後,它變成了後驗分佈,這是貝葉斯定理給出的說法,也就是貝葉斯定理的全部。
這與傳統科學運作的方式相背離。這就像在說:「實際上,哥白尼和托勒密都不對;讓我們只預測星球未來的軌跡,假定地球繞著太陽轉,反過來也成立,然後對結果取平均值。」
當然,這是一個加權平均值,假設作為其後驗概率的權值,那麼能更好地解釋數據的假設會更有價值。另外,就像玩笑說的那樣,加入貝葉斯學派意味著絕不用說你對某事很肯定。
不用說,攜帶不止一個而是大量的假設是一種巨大的痛苦。在掌握貝葉斯網絡的例子中,我們做預測的方法應該是對所有可能的貝葉斯網絡取平均值,包括所有可能的圖形結構,以及每個結構的所有可能的參數值。在某些情況下,我們可以以封閉形式對參數取平均值,但因為各種結構,進行得不順利。舉個例子,我們可以將馬爾可夫鏈蒙特卡洛理論運用到網絡的空間中,隨著馬爾可夫鏈的發展,從這個可能的網絡跳到另外一個網絡。將該複雜性與計算成本和貝葉斯有爭議的概念(真的沒有所謂的客觀事實)結合起來,就不難知道為什麼20世紀頻率論一直主導科學界。
然而貝葉斯法還是有可取之處的,其中有一些主要原因。可取之處在於,很多時候,幾乎所有的假設都會以微小的後驗概率作為結尾,而我們可以安然地忽略它們。實際上,只考慮單個最可能的假設通常是一種非常好的近似方法。假設我們對於拋硬幣問題的先驗分佈是:正面朝上的所有概率均相等。看到連續拋硬幣的結果,這個效果是將分佈越來越多地集中到與數據最為一致的假設上。例如,如果h包含正面朝上的可能概率,且一枚硬幣正面朝上的概率為0.7,我們會看到圖6–6。
每次拋完硬幣的後驗概率變成拋下一次硬幣的先驗概率,拋了一次又一次,我們越來越肯定h=0.7。如果我們只認準這一單個最可能假設(在這個例子中,h=0.7),這樣貝葉斯法和頻率論法就變得很相似,但有一個關鍵的不同點:貝葉斯學派考慮先驗的P(假設),而不僅僅是可能性P(數據∣假設)〔數據先驗P(數據)可以忽略,因為它對於所有假設來說都一樣,所以不會影響獲勝者的選擇〕。如果我們願意假定所有的假設都和先驗概率均等,那麼貝葉斯法現在就簡化為極大似然法。因此貝葉斯學派可以對頻率論者說:「看,你做的僅是我們所做部分工作的特例,但至少我們能夠使自己的假設清楚明白。」而如果假設與先驗概率不均等,那麼極大似然法的隱含假設(假設和先驗概率均等)會給出錯誤的答案。
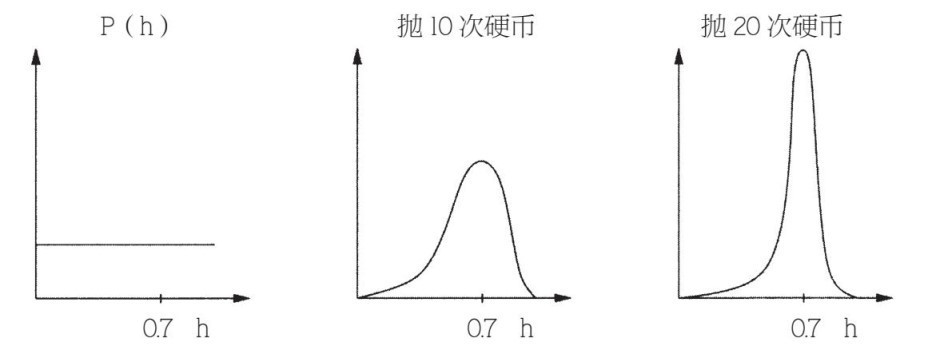
圖6–6
這就像一場理論性的討論,卻得出驚人的實踐性結果。如果我們只看了一次拋硬幣,而結果是正面朝上,極大似然理論會說正面朝上的概率是1。這可能非常不準確,而當硬幣反面朝上時,會讓我們措手不及。一旦我們看過很多拋硬幣行為,估算起來就更可靠,但在許多問題中,我們無法看到足夠多次數的「拋硬幣」,無論數據有多大。假定單詞「supercalifragilisticexpialidocio us」在我們的訓練數據中從未在垃圾郵件中出現過,而是出現在一封討論《歡樂滿人間》的郵件中。接下來,包含極大似然概率估算功能的樸素貝葉斯垃圾郵件過濾器會決定包含該詞的郵件不是垃圾郵件,儘管郵件中的其他詞喊著:「垃圾郵件!垃圾郵件!」相反,貝葉斯學派會賦予這個詞較低但非0的概率,讓其出現在垃圾郵件中,同時允許其他詞語將其覆蓋。
如果我們努力掌握貝葉斯網絡的結構和它的參數,問題只會變得更糟糕。我們可以通過爬山法來做到這一點,由空的網絡(沒有箭頭)開始,添加最能提高可能性的箭頭,以此類推,直到箭頭不再起改善作用。遺憾的是,這很快就會引起大範圍過擬合,網絡會將零概率分配給未在數據中出現的所有狀態。貝葉斯學派可以做更有意思的事情。他們可以利用先驗分佈來編碼專家對該問題的觀點——他們對休謨問題的回答。例如,我們可以為醫學診斷設計一個原始貝葉斯網絡,方法就是採訪醫生,詢問他們哪些症狀可能會對應哪些疾病,並添加相應的箭頭。這就是「先驗網絡」,而先驗分佈可以通過添加或移除箭頭的數量來懲罰替代網絡。醫生也不是完全可靠的,所以我們讓數據來覆蓋它們:如果通過添加數據來提高可能性比懲罰重要,我們會做這件事。
當然,頻率論者正意識到這個問題,而且他們的回答,舉個例子,是通過某因素來增加可能性,該因素會懲罰更多的複雜網絡。但這時候頻率論和貝葉斯學派就無法區別了,而你把計分函數稱作「懲罰似然」還是「後驗概率」就是喜好的問題了。
儘管頻率論者和貝葉斯學派在一些問題上存在分歧,對於概率的含義也存在哲學上的差異。認為概率包含主觀性讓許多科學家感到略有不安,但如果沒有這一點,很多用途就被禁止了。如果你是頻率論者,那麼只能對那些發生次數超過一次的事件的概率進行估算。所以像「希拉裡·克林頓在下一輪總統競選中打敗傑布·布什的概率是多少」這樣的問題則無法回答,因為沒有哪場競選的目的是讓他們互相競爭。但對於貝葉斯學者來說,概率是包含主觀程度的信任,所以他可以自由地做有根據的猜測,而且推理演算會使他所有的猜想都一致。
貝葉斯法不僅僅適用於學習貝葉斯網絡,還適用於其特殊情況(相反,儘管它們的名字如此,貝葉斯網絡並非一定就是貝葉斯學派的:頻率論者也可以掌握它們,正如我們剛看到的那樣)。我們可以將先驗分佈置於任意級別的假設中(規則組、神經網絡、程序)然後在給定數據的條件下,利用假設的可能性來對其進行更新。貝葉斯學派的觀點就是,選擇什麼表示方法由你決定,但得利用貝葉斯定理來掌握它。20世紀90年代,他們聲勢浩大地接管了神經信息處理系統國際會議(NIPS),即聯結學派研究的主會場。其中的罪魁禍首(可以這麼說)包括大衛·麥凱、雷德福·尼爾、邁克爾·喬丹。麥凱是英國人,是加州理工學院約翰·霍普菲爾德的學生,後來成為英國能源部的首席科學顧問,他表明了如何通過貝葉斯法來學習多層感知器。尼爾向聯結學派介紹MCMC,而喬丹則向他們介紹變分推理。最終,他們指出在限制範圍內,你可以在多層感知器中「集中」神經元,剩下一種未提到它們的貝葉斯模型。不久以後,在向NIPS提交的論文中,「神經的」一詞很好地表達了「拒絕」的意思。有些研究人員開玩笑稱,該會議應該改名為BIPS,即「貝葉斯信息處理系統」(Bayesian Information Processing Systems)。
馬爾可夫權衡證據
但在通往統治世界的路上發生了有趣的事情。利用貝葉斯模型的研究人員注意到,如果你用非法的方式來調整概率,得出的結果會更好。例如,在語音識別器中,通過調整P(詞語)可以提高準確率,但它就不再是貝葉斯定理了。發生了什麼?結果是,問題的原因在於生成模型做出的錯誤獨立性假設。簡化的圖形結構使模型變得可掌握,而且值得保留,不過因為手頭任務,我們最好只掌握自己能力範圍內的最佳參數,無論它們是否為概率。樸素貝葉斯法的一個真正優勢在於,可以提供少量而有信息量的特徵,通過這些特徵可以預測級別。另外,它還可以提供快速、穩健的方法來掌握相應的參數。在垃圾郵件過濾器中,每個特徵都是某個特定的詞語出現在垃圾郵件中,而相應的參數是它發生的頻率是多少,對於非垃圾郵件也是同樣的道理。以這種方式來看,考慮到把最佳預測變成可能,甚至在很多情況下其獨立性假設受到嚴重違背,樸素貝葉斯可能是最優的。當我意識到這一點,並於1996年發表一篇關於它的論文時,人們對於樸素貝葉斯的懷疑消解了,並幫助它取得成功。但它也向不同的模型邁出了一步,該模型在過去20年中已漸漸取代貝葉斯網絡,它就是馬爾可夫網絡。
馬爾可夫網絡是一組特徵以及對應的權值,特點和權值共同定義概率分佈。特徵可以和「這是一首民歌」一樣簡單,也可以與「這是一首由嘻哈藝術家創作的民歌,有薩克斯的重複樂段和遞降的和弦部分」一樣複雜。潘多拉利用一大組特徵,它將其稱為「音樂基因組計劃」,目的是為你挑選要播放的歌曲。假定我們將它們與馬爾可夫網絡接通,那會怎麼樣?如果你喜歡民歌,相應特徵的權值會上升,而當你打開潘多拉時,更有可能聽到民歌。如果你也喜歡聽嘻哈藝術家創作的歌曲,該特徵的權值也會上升。這時你最有可能聽到的歌曲同時包含這兩種特徵,即民歌和嘻哈藝術家的創作特點。如果你不喜歡民歌或者不喜歡嘻哈藝術家本身,而只喜歡兩者的結合,那麼你想要的是具備更加複雜特徵的「嘻哈藝術家創作的民歌」。潘多拉的特徵由手工創造,但在馬爾可夫網絡中我們也可以利用爬山法來掌握特徵,這與規則歸納相似。不管怎樣,梯度下降是掌握權值的一種好方法。
像貝葉斯網絡一樣,馬爾可夫網絡可以通過圖表來表示,但它們用無向弧而不用箭頭。兩個變量被聯結起來,這意味著它們會直接相互依賴,如果它們一起出現在某個體征中,例如,「由嘻哈藝術家創作的民歌」中的「民歌」和「由嘻哈藝術家創作」。
馬爾可夫網絡在許多領域中能起到主要作用,例如,計算機視覺。舉個例子,一輛無人駕駛車輛需把看到的每張圖片分成道路、天空、村莊三個部分。有一個選擇就是根據其顏色,將每個像素標記為三個部分中的一個,但這種選擇不夠好。圖片充滿嘈雜因素和變量,車輛會出現幻覺,想像道路旁佈滿岩石,還有天空中出現的一段段公路。但是我們知道,圖片中近似的像素通常屬於同一物體,而我們可以引入相應的一組特徵:對於每一對相鄰像素,如果它們屬於相同物體,則特徵是真的,否則是假的。現在有大段連續街區公路和天空的圖片比沒有這些的圖片更有可能,並且車會直走,而不是不斷左右轉向來避開想像中的岩石。
馬爾可夫網絡可以經過訓練,來最大化整個數據的可能性,或者在知道某些信息的情況下,將我們想預測的事情的可能性最大化。對於Siri來說,整個數據的可能性是P(單詞、聲音),而我們感興趣的條件可能性是P(單詞|聲音)。通過優化後者,我們可以忽略P(聲音),因為這個概率只會使我們偏離目標。既然我們忽略它,它可以是任意複雜的。這比HMM不切實際的猜想要好得多:聲音只依賴於對應的單詞,不會受到周圍環境的任何影響。實際上,如果Siri的所有關心找出你剛才說的話,可能它甚至就不用擔心概率問題了。它只要確保在計算它們特徵權值的總和時,正確單詞的得分會比錯誤單詞的得分高,而且為了保險,要高出很多。
類推學派用這種推理方式得出其邏輯結論,正如我們在第七章將看到的那樣。在21世紀的前10年,他們反過來接管NIPS。現在聯結學派打著深度學習的旗號再次佔據主導地位。有些人說研究總是處於循環狀態,但它更像一個螺旋,閉環沿著前進的方向繞。在機器學習中,螺旋會收斂至終極算法。
邏輯與概率:一對不幸的組合
你可能認為貝葉斯學派和符號學派相處得很好,因為考慮到他們都相信學習的第一原理方法,而不相信自然啟發的方法。事實遠不是這樣,符號學派不喜歡概率,而且會開這樣的玩笑:「換個電燈泡需要多少個貝葉斯學者?他們不確定。細想一下,原來他們是不確定燈泡是不是燒壞了。」更嚴肅地說,符號學派指出我們因為概率而付出的高昂代價。推理突然變得更加珍貴,所有那些數據都變得難以理解,我們得處理好先驗概率,一大批「殭屍」假設會永遠追著我們。短時間內將分散知識集中起來的能力,對於符號學派來說是多麼重要,卻已經消失。最糟糕的是,我們不知道如何對自己想學習的很多東西進行概率分配。貝葉斯網絡是在變量的一個矢量上的分佈,但在網絡、數據庫、知識庫、語言、計劃、計算機程序上的分佈呢?所有這些在邏輯中都易於處理,而無法掌握它們的算法明顯就不是終極算法。
反過來,貝葉斯學派指出了邏輯的脆弱性。如果我有一條規則,如「鳥會飛」,沒有哪個世界會存在不會飛的鳥。如果我想補充一下,加上例外條件,例如,「鳥會飛,除非它們是企鵝」,那麼這些例外條件永遠都說不完(鴕鳥呢?籠中鳥呢?死鳥?斷了翅膀的鳥?翅膀濕了的鳥?)。有個醫生診斷你得了癌症,而你想聽不同的意見。如果第二個醫生不同意,你就陷入困境了。你無法權衡這兩種觀點,只能兩個都相信。然後發生了一場災禍:豬會飛,永恆運動成為可能,而地球則不再存在,因為在邏輯當中,任何事都可以從矛盾中推理出來。再者,如果知識是從數據中掌握得來的,那麼我就無法肯定它是對的。為什麼符號學派卻假裝肯定?無疑休謨會對這樣漫不經心的態度感到不滿。
貝葉斯學派和符號學派一致認為,先驗假設不可避免,但對於他們認可的先驗知識種類卻存在分歧。對於貝葉斯學派來說,知識越過模型的結構和參數,進入先驗分佈中。原則上,之前的參數可以是任意我們喜歡的值,但諷刺的是,貝葉斯學派趨向於選擇信息量不足的先驗假設(比如將相同概率分配給所有假設),因為這樣更易於計算。在任何情況下,人類都不是很擅長估算概率。對於結構這方面,貝葉斯網絡提供直觀的方法來整合知識:如果你認為A直接引起B,那麼應把箭頭從A指向B。但符號學者則要靈活得多:作為先驗知識,你可以為自己的學習算法提供任何能用邏輯編碼的東西,實際上,所有東西都可以用邏輯編碼,只要它是黑白色的。
顯然,我們既需要邏輯,也需要概率。治癒癌症就是一個很好的例子。貝葉斯網絡可以從單個方面模仿細胞如何起作用,就像基因調節和蛋白質折疊那樣,但只有邏輯可以將所有碎片組合到一張連貫的圖片中。此外,邏輯無法處理不完整或包含嘈雜因素的信息,這在實驗生物學中較普遍,但貝葉斯網絡可以沉著地處理這個問題。
貝葉斯學習能對單個數據表起作用,表中的每列表示一個變量(例如,一個基因的表達水平),而每行表示一個實例(例如,一個微陣列實驗,包含每個基因被觀察到的水平)。如果表格有「漏洞」和測量誤差,不要緊,因為我們可以利用概率推理來彌補漏洞,然後對誤差取平均值。但如果我們擁有的表格超過一個,那麼貝葉斯學習就會停滯不前。例如,它不懂如何將基因表達的數據與DNA片段轉譯成蛋白質的數據結合起來,也不知道那些三維形狀的蛋白質如何反過來使它們鎖定到DNA分子的不同部分中,同時影響其他基因的表達。利用邏輯,我們可以輕易地寫出與所有這些方面相關的規則,然後通過結合相關表格來對它們進行學習,但唯一的條件就是表格沒有任何漏洞或者誤差。
將聯結學派和進化學派結合起來很簡單:只要改善網絡結構,利用反向傳播來掌握參數。但將邏輯和概率統一起來要困難得多。最早嘗試這麼做的人是萊布尼茨,他是邏輯和概率的開拓者。還有一些19—20世紀最偉大的哲學家和數學家,比如喬治·布爾和魯道夫·卡爾納普,他們都努力想解決這個問題,但最終沒有走得很遠。最近,計算機科學家和人工智能研究人員加入了這場爭論。隨著21世紀的到來,我們取得的最好成果也是不完整的,比如將一些邏輯結構加入貝葉斯網絡中。多數專家相信,將邏輯和概率相統一是不可能的。尋求一個終極算法的前景並不樂觀,特別原因在於,當前進化學派的和聯結學派的算法無法處理不完整的信息和多數據組。
幸運的是,我們已經攻克了這個難題,而終極算法現在看起來離我們更近了。在第九章中,我們會看到人類是如何做到這一點的,並做出推斷。首先,我們要找到已丟失的那張很重要的拼圖:如何學習小數據。在當下數據洪流的背景下,可能這顯得沒有必要,但實際上我們常常會發現,自己有很多關於要解決問題的數據,而關於其他問題的數據則幾乎沒有。這是機器學習中最重要的思想之一流行起來的原因:類比思想。到目前為止,我們談到的所有學派有一個共同點:他們都學習研究中的現象的顯式模型,無論它是一組規則、一個多層感知器、一個基因計劃,還是一個貝葉斯網絡。當他們沒有足夠的數據來做這件事時,就會被難住。但類比學派可以從甚至小到一個例子的數據中學習,因為他們絕不會形成一種模式。下面,讓我們看看他們是怎麼做的。