機器學習既是科學,也是技術,兩者的特點提示我們如何將其統一起來。在科學方面,理論的統一往往從看似簡單的觀察開始。兩個看似不相關的現象原來只是同一枚硬幣的兩面,就像第一張倒下的多米諾骨牌,會引起其他許多牌倒下。蘋果落到地上,月亮懸掛在夜空,這兩者都是由重力引起的,而且(無論是否杜撰)一旦牛頓弄明白這些現象的原因,重力最後也可以用來解釋潮汐、分點歲差、彗星軌道等其他很多現象。在日常體驗中,電和磁絕不會同時出現:這邊有閃電的火花,那邊有吸住鐵製品的岩石,兩種現象都很少見。可是一旦麥克斯韋弄清楚電場的改變會產生磁性,反之亦然,顯然閃電是兩者親密的媒介。現在我們知道,電磁並不罕見,遍及所有物質。門捷列夫的元素週期表不僅將所有已知物質僅分成兩個維度,也預示哪裡會有新元素。達爾文在貝格爾號上的觀察突然得到理解,因為馬爾薩斯的《人口論》表明了自然選擇這一組織原理。
當克裡克和沃森偶然發現雙螺旋結構可用於解釋DNA令人迷惑的屬性時,他們馬上就看到DNA可能會如何複製自身,而生物學由「集郵」(盧瑟福用的貶義詞)到「統一科學」的過渡開始了。在這些例子中,各種各樣令人眼花繚亂的觀察結果原來都有同一個相同的起因,而一旦科學家們明確了這個起因,就可以反過來利用它來預測許多新的現象。同樣的道理,雖然我們在本書中見到的學習算法似乎差別很大——有些以大腦為基礎,有些以進化為基礎,有些則以抽像的數學原理為基礎,但實際上,它們有很多相似之處,而由學習產生的理論會有許多新的觀點。
雖然知道這一點的人比較少,但世界上許多最重要的技術都是創造統一物的結果,該統一物是單一機制,能完成之前需要很多機制完成的事情。互聯網,正如它的名字一樣,是連接相互網絡的一種網絡。沒有它,每種類型的網絡就得需要一個不同的協議來與其他每個網絡進行對話,這就很像對於世界上每種不一樣的語言都需要一本不一樣的字典。互聯網協議就是一種世界語言,會給每台計算機能與其他所有計算機直接對話的錯覺,世界語言還允許電子郵件和網頁忽視那些它們無法起到影響作用的基礎設施建設的細節。關係數據庫也會對企業應用做類似的事情,允許開發商和用戶依據抽像關聯模型進行思考,並忽略關於回應搜尋計算機所嘗試的方式。微處理器是一種數據電子元件裝配,可以對所有其他裝配進行模仿。虛擬機允許同一台計算機同時在100個人面前偽裝成100台不同的計算機,並使雲成為可能。圖形用戶界面讓我們編輯文件、數據表、幻燈片以及別的很多東西,利用Windows操作系統、菜單、鼠標單擊的通用語言。計算機本身就是統一物:單個設備可解決任何邏輯或者數學問題,只要我們知道如何對它進行編程。甚至電也是一種統一物:你可以通過許多不同的來源來獲取它——煤、天然氣、核能、水力、風力、太陽,然後以無限多種的方式來消耗它。一座發電站不會知道或者關心它生產的電會如何被消耗掉,而你的門廊燈、洗碗機或者全新的特斯拉也不會在意電力供應來自哪裡。電力就是能源的世界語言。終極算法是機器學習的統一物:它讓任意應用利用任意學習算法,方法是將學習算法概括成通用形式——所有應用都需要知道該形式。
我們邁向終極算法的第一步會簡單得令人意外。事實證明,要將許多不同的學習算法結合成一個並不難,利用的就是元學習。網飛公司、沃森、Kinect以及其他無數公司都會利用它,而它在機器學習算法的箭袋中也是最有力量的一支。它還是接下來要進入的深層次統一的墊腳石。
萬里挑一
這裡有一個挑戰:你有15分鐘用來聯合決策樹、多層感知器、分類器系統、樸素貝葉斯,以及支持向量機,使其變成擁有每個部分最佳屬性的單一算法。快!你能做什麼?顯然,這不能涉及單個算法的細節。沒有時間了,但接下來怎麼辦?把每種學習算法當成委員會上的一位專家,每個人都仔細觀察待分類的實例——這個患者的診斷是什麼,然後有把握地做出預測。你不是一位專家,卻是委員會主席,你的工作就是把他們的意見結合成一個最終決定。你手上的問題其實就是一個新的分類問題,這種情況下,輸入不是患者的症狀,而是專家的觀點。但你可以將機器學習以同樣的方式運用到解決這個問題上,專家也會這樣將其運用到最初的問題上。我們可以稱其為元學習,因為它就是要瞭解學習算法。元學習算法本身可以是任意學習算法,從決策樹到簡單的權值投票。為了掌握權值或者決策樹,我們利用學習算法的預測來代替每個最初例子的屬性。經常能夠準確預測類別的學習算法會取得較高的權值,而不準確的那些則容易被忽略。有了決策樹,是否要利用學習算法可能會依照其他學習算法的預測來定。不管怎樣,為了給既定訓練例子獲取學習算法的預測,我們首先必須將其運用到原始訓練集「排除該樣本」中,然後利用最終的分類器,否則委員會就有被擬合學習算法控制的風險,因為它們可以通過記憶類別來預測準確的類別。網飛獎獲得者利用元學習來結合數百個不同的學習算法;沃森利用它來從備選項中選擇最終的答案;內特·希爾也以相似的方式將投票與預測選舉結果結合起來。
這種類型的元學習被稱為「堆疊」,是大衛·沃爾珀特的創見,在第三章中我們提到過他,他是「天下沒有免費的午餐」定理的創造者。還有一個更簡單的元學習算法是「裝袋」算法,由統計學家裡奧·佈雷曼發明。「裝袋」算法通過重新取樣的方法來產生訓練集的隨機變量,將同樣的學習算法應用到每個訓練集中,然後通過投票將結果結合起來。做這件事的原因是它可以減少變量:組合模型和任何單一模型相比,對於變幻莫測的數據的敏感度要低得多,這樣提高準確度就變得很容易了。如果模型是決策樹,且我們通過保留屬性(這些屬性因考慮每個節點而得來)的任意子集來進一步改變這些決策樹,那麼所得結果就是所謂的隨機森林。隨機森林到處是一些準確的分類器。微軟公司的Kinect利用它們來弄清楚你在做什麼,而且它們會經常在機器學習比賽中獲勝。
最聰明的元學習算法之一就是推進,由兩位學習領域的理論家約阿夫·弗羅因德和羅伯·夏皮爾創造。推進算法不是通過結合不同的學習算法,而是將相同的分類器不斷應用到數據中,利用每個新的模型來糾正前面模型的錯誤。它通過將權值分佈給訓練實例的方式來完成這件事。每個被誤分類的權值,在每輪學習過後都會增長,使得後面的幾輪會更向它集中。推進算法的名字源於這樣的想法:該過程可以推進只比隨機猜測好一點的分類器,但如果持續如此,就會接近完美。
元學習非常成功,但它卻不是深入組合模型的方法。另外,它也昂貴、苛刻,因為會做很多輪學習,而且組合模型可能會很難懂(「我認為你有前列腺癌,因為決策樹、遺傳算法、樸素貝葉斯算法都這麼判斷,雖然多層感知器和支持向量機反對」)。此外,所有的組合模型確實只是一個巨大而凌亂的模型。難道我們不能找到完成同樣任務的單一學習算法嗎?當然可以。
終極算法之城
我們的統一學習算法也許通過延伸寓言可以得到最好的介紹。如果機器學習是一塊大陸,被分成5個區域,那麼終極算法就是首都城市,矗立在5個區域會合的特殊地帶。如果從遠處接近它,你會看到這個城市由3個同心圓組成,每個圓被一堵牆圍著。外圍的圓,也是最寬的圓是「優化城」。這裡的每個房間就是一種算法,而且它們有不同的形狀和面積。有些房子在建設中,當地人忙著圍著它團團轉;有些房子非常嶄新;有些房子則看起來老舊荒廢。山的更高處是「評價城堡」,命令不斷從它的大廈和宮殿向下面的算法發出。最重要的是,在天空的映襯下,「代表法之塔」矗然而立,這裡住著城市的統治者。他們的城市有不可改變的法律,不僅規定在城市範圍內,而且規定了在整個大陸什麼能做、什麼不能做。在中央,最高的塔尖飄揚著終極算法的旗幟,顏色是紅和黑,上面的五角星圍著我們無法理解的文字。
這座城市被分成5個區域,一個區域屬於一個學派。每個區域從「代表法之塔」一直延伸至城市的外牆,包圍了塔、「評價城堡」裡的一群宮殿,以及它們俯瞰的「優化城」的街道和房屋。這5個區域和3個圓圈將城市劃分成15個區域、5種形狀,以及你需要解決的那15塊拼圖(見圖9–1)。
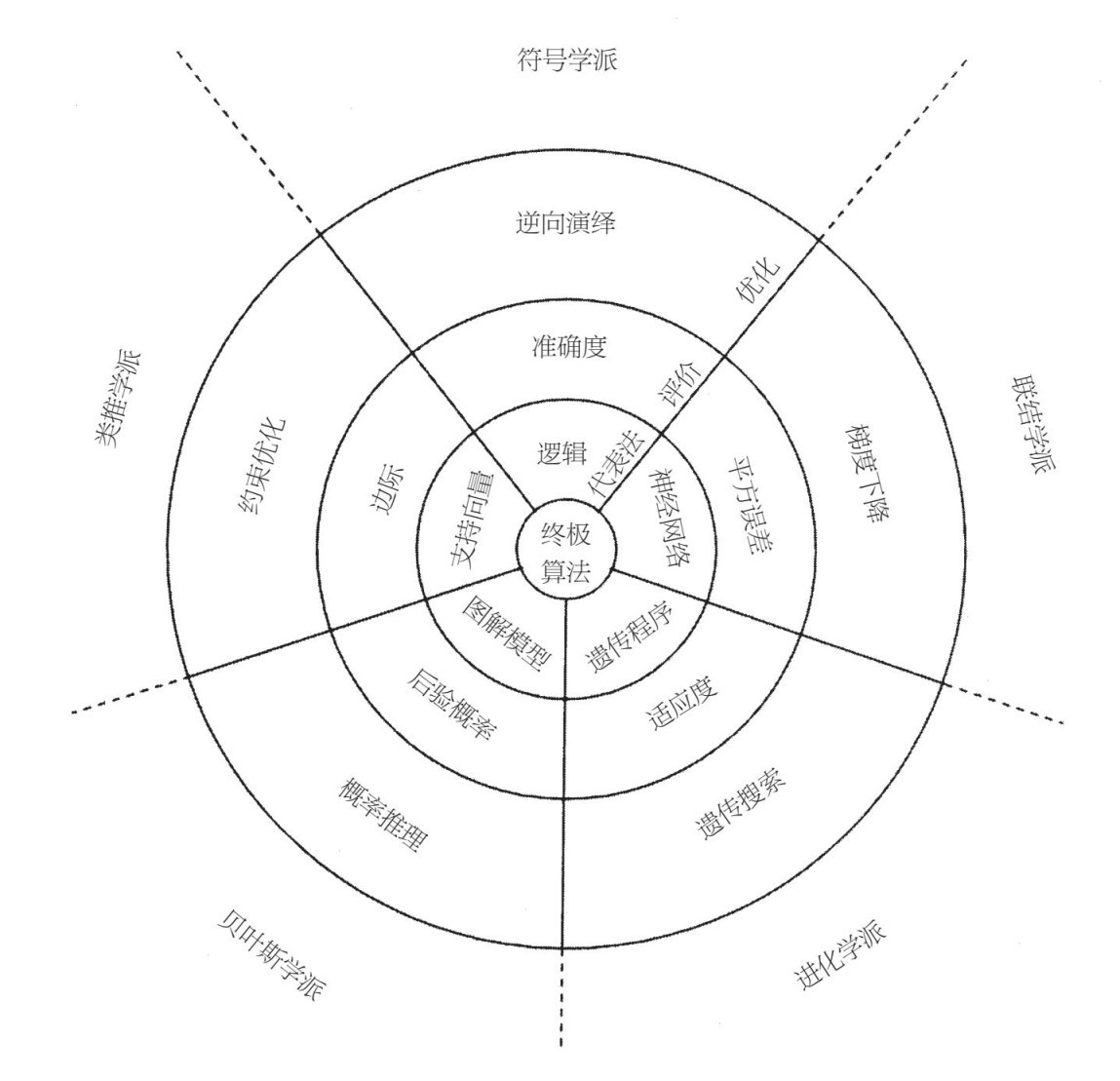
圖9–1
你專注地盯著地圖,試圖解開它的謎底。15塊拼圖都很完美地拼在一起,但你得弄清楚它們是如何結合起來的,且只分成3個區域:終極算法的代表方法、評價、優化部分。每種學習算法都有這3個部分,但不同學派也會有不同的組成部分。
代表法是一種形式語言,利用這種語言,學習算法會表達它的模型。符號學派的形式語言是邏輯,其中規則和決策樹是特殊例子。聯結學派的是網絡神經。進化學派的是遺傳程序,包括分類器系統。貝葉斯學派的是圖解模型,這是貝葉斯網絡和馬爾可夫網絡的涵蓋性術語。類推學派的是特例,可能會有權值,就像在支持向量機中那樣。
進化學派的主要部分是評分函數,判斷一個模型的優劣程度。符號學派用的是準確度或者信息增益。聯結學派利用的是連續誤差測量,例如,平方誤差,這是預期值與真實值之間差異的平方的總和。貝葉斯學派利用的是後驗概率。類推學派(至少是支持向量機這種類型)利用的是邊界。除了模型與數據的匹配度,所有的學派都會考慮其他合意的屬性,例如模型的簡潔度。
優化是一種算法,即尋找最高得分的模型,並回歸它。符號學派的特色搜索算法是逆向演繹。聯結學派的是梯度下降。進化學派的是遺傳搜索,包括交叉和突變。貝葉斯學派在這方面不同尋常:他們不只是尋找最好的模型,而是尋找所有模型的平均值,由它們的可能程度來權衡。為了有效進行加權,他們利用諸如MCMC之類的推理算法。類推學派(或者更準確地說是支持向量機)利用約束優化來找到最佳模型。
經過一天的跋涉之後,太陽快速接近地平線,而你要在天黑前加快速度。城市的外圍牆有5個大門,每個門由一個學派掌控,並通往每個學派在「優化城」裡的區域。對著防護裝置念出「深度學習」的口令之後,我們進入「梯度下降大門」,並旋轉進入「代表法之塔」。大街從門口處突然沿著山坡上升,一直延伸到城堡的「平方誤差大門」,但你卻要向左轉向進化區域。梯度下降區域的房子都是平滑曲線以及密切交織在一起的模式,看起來幾乎更像一個叢林,而不是一座城市。但當梯度下降屈服於遺傳搜索時,情況就會急劇變化。到這裡時,房屋會升得更高,一層結構堆在另一層之上,但這些結構稀少,幾乎沒有,似乎等著由梯度下降的曲線來填滿。就是這樣:結合兩者的方法就是利用遺傳搜索來找到模型的結構,然後讓梯度下降來填滿它的參數。這就是自然所做的事:進化創造大腦結構,而個人經歷則對這些結構進行調整。
第一步完成了,你急忙趕往貝葉斯區域。即使在遠處,你也可以看到它如何簇擁著「貝葉斯定理大教堂」,「MCMC小巷」一路蜿蜒曲折。這個過程需要一段時間。你抄近道走上「置信傳播街道」,但似乎它永遠在繞圈循環,然後你看到它了——「最可能大道」向著「後驗概率大門」傲然屹立。不用對所有模型求均值,你可以直接奔向最適合的那個,並相信最終的預測會幾乎一樣。而你可以讓基因搜索選擇模型的結構和梯度下降作為其參數。輕輕鬆了一口氣,你意識到這就是你需要的所有概率推理,至少持續到開始利用模型回答問題的時候。
你不斷向前走。約束優化區域是窄巷和死胡同組成的迷宮,各種各樣的例子到處緊挨,偶爾會對支持向量的周圍進行清理。顯然,為了避免遇到錯誤類別的例子,你要做的就是將限制條件添加到已經聚合的優化控制器中。但回頭想想,這並不一定有必要。現在想起來了,甚至這也沒必要。當我們學習支持向量機時,為了避免過擬合,已經讓邊際受到侵犯,只要每次違反就會受到懲罰。在這種情況下,優化例子權值可以再次通過梯度降低的形式來確定。這很容易,你覺得自己開始對它有所瞭解了。
實例稠密的排名突然中斷,你發現自己在逆向演繹區域,這裡有寬闊的大街和古代的石頭建築。這裡的建築是幾何學的、樸素的,由直線和直角組成。即使經過很大程度修剪的樹有矩形的樹幹,但它們的葉子被細緻地貼上預測的類別。該區域的居民似乎用特殊的方式在建造他們的房子:他們從屋頂開始,將屋頂標識為「結果」,並漸漸地將天花板與地板之間的空隙填補,他們將地板標識為「前提」。一個接一個地,他們找到一塊恰好與某個空隙吻合的石頭,然後將其移到合適的位置。但你注意到,許多空隙有同樣的形狀,而在這些石頭形成該形狀之前,切割並整合石頭也許會更快,然後盡可能多地盯住客人。換句話說,你可以利用遺傳搜索來進行逆向演繹。巧妙!你似乎已經將那5個優化程序總結為一個簡單的方法:遺傳搜索用於結構,而梯度下降用於參數。即使那樣也可能過分了。對於很多問題,如果你做3件事,可以將遺傳搜索簡化為爬山法——省去交叉,在每一代中嘗試所有可能的點突變,並一直選擇單個最優假設來為下一代播種。
頭頂的雕像是什麼?亞里士多德。他不以為然地看著那1/4梯度下降混亂地糾纏在一起。你已經充分進行循環,擁有了為得到終極算法而需要的統一優化器,但來不及慶祝一下,夜幕降臨了,你要做的還有很多。通過壯觀但相當狹窄的「準確度之門」,你進入「評價城堡」。門上的銘文寫著:「汝等進入此地,須棄絕過擬合之希望。」隨著你循環經過5個學派鑒別器的宮殿,在心理上將每個部分歸位。為了連續性預測,你利用準確度來評價「是」或「否」預測以及平方誤差。適應度只是進化學派用來指代評分函數的名字,你可以將它當作你想到的一切,包括準確度和平方誤差。如果你忽略先驗概率,而且誤差遵循正態分佈,那麼後驗概率會簡化為平方誤差。如果你允許它因為價格而受到違反,邊際就會變成準確度更加柔軟的版本——對於準確的預測不是不進行懲罰,對於不準確的預測則基於懲罰,懲罰一直等於零,直到你進入邊際,這時它開始平穩增長。喲!結合鑒別器比結合優化器要簡單得多,但「代表法之塔」落停在你上空,給你一種不祥的預感。
你進入搜尋的最後階段,打開「支持向量之塔」的門,一位看起來面目猙獰的警衛打開它,你突然意識到自己看不到密碼。「核心。」你脫口而出,努力使聲音不顯得絲毫慌張。警衛鞠躬然後避開。重新獲得士氣後,你走進去了,並會因為自己的粗心而踢自己一腳。塔的第一層是裝修豪華的環形室,還有似乎為支持向量機的大理石表達法佔據中心的重要位置。當你在它周圍走時,注意到遠的那邊有一個門,它一定能夠通過中心塔——「終極算法之塔」。門口似乎沒有警衛,你打算抄近道,悄悄溜過門廊,走到一條不長的走廊,發現自己置身在一間更大的五角房屋中,每堵牆上都有一扇門。在中心,一個螺旋狀的樓梯上升至你可以看到的位置。你聽到上面的聲音,然後躲進對面的門裡。這個門通往「神經網絡之塔」。你再一次進入環形的房間,這個房間的中心有一個多層感知器作為裝飾品,它的組成部分和支持向量機不一樣,但佈局十分相似。你突然發現,支持向量機只是一個這樣的多層感知器:有一個由內核而不是S曲線組成的隱藏層,還有一條輸出信息,是一個線性組合,而不是另外一條S形曲線。
難道說別的表示方法也有相似的形式?越來越覺得刺激。你穿過五角星房屋,跑回「邏輯之塔」。看著中心一組規則的描述,你試著辨別一個模式。是的!每條規則只是一個高度程式化的神經元。例如,如果規則是「一隻巨大的爬行動物,然後會噴火,那麼它就是一條龍」,對於「它是一隻巨大的爬行動物」和「噴火」以及門檻值1.5來說,僅僅是權值為1的感知器。一組規則集就是一個有隱藏層的多層感知器,包含每條規則的每個神經元,以及形成規則的稀缺的輸出神經元。在腦海深處有一個疑問,但你現在沒有時間解決它。當你穿過五角房屋走到「遺傳程序之塔」時,就已經可以看到如何對它們進行合併。遺傳程序也只是程序,而程序只是邏輯構造。房屋中遺傳程序的雕塑是樹的形狀,子程序會分成更多的子程序,當你仔細看葉子時,會發現它們只是簡單的規則。因此程序歸結為規則,而且如果規則可以簡化為神經元,那麼程序也可以。
不幸的是,在「圖解模型之塔」的頂部,環形房屋內的雕像與其他的看起來大不一樣。圖解模型是各種因素的一個產物:條件概率(在貝葉斯網絡條件下)以及狀態的非負函數(在馬爾科夫網絡條件下)。儘管很努力,你就是看不到神經網絡或者規則集之間的連接,失望向你侵襲而來。不過你又戴上「護目鏡」,其算法可以代替每個函數。有了!此時各種因素的產物就是術語的總和,就像一個支持向量機、一個投票規則集或者一個多層支持向量機,沒有輸出S形曲線。例如,你可以將一個樸素貝葉斯龍分類器解釋成一個感知器,對於「噴火」,它的權值等於P(噴火∣龍)的log值減去P(噴火∣不是龍)的log值。當然,圖解模型比這個還要概括,因為它們可以代表許多變量的概率分佈,而不僅僅是給定其他變量(屬性)情況下的一個變量(類別)分佈。
你做到了!還有疑問?吸收支持向量機變成神經網絡,吸收神經網絡變成圖解模型:起作用了。那麼一定要吸收遺傳程序變成邏輯。但將邏輯和圖解模型結合在一起?此處有一點差錯。你終於看到問題所在:邏輯有一個維度,而圖解模型沒有,反過來也一樣。五個房屋中的雕塑匹配是因為它們是簡單的寓言,但事實並非如此。圖解模型不會讓我們表示規則時涉及的對象超過一項,就像「朋友的朋友是朋友」,它們所有的變量必須是來自同一對象的屬性。它們也不能代表任意程序,因為這些程序會通過一組組通過來自這個和那個子集的變量。邏輯可以輕易做到這些事,但它無法代表不確定、模糊或者相似度。而且如果沒有一種能做所有這些事的表示方法,就無法獲得通用學習算法。
你絞盡腦汁想辦法,但你越努力,問題就變得越棘手。也許將邏輯和概率統一起來超出了人類的能力。筋疲力盡的你漸漸入睡。突然,一聲低沉的吼叫把你吵醒了。一隻多頭複雜怪物撲向你,張牙舞爪,你在最後一刻躲開了。你用學習這把劍猛擊怪物,這是唯一能殺死怪物的武器,最後你贏了,把它所有的頭砍了下來。趁它還沒長出新的頭,你跑上了樓。
艱難地攀爬之後,你到達樓頂。此時有一場婚禮正在進行。珀萊爾迪卡特斯(Praedicatus,邏輯領域的大臣、象徵界的統治者以及程序的保護神)對馬爾科維雅(Markovia,概率領域的公主、網絡界的女皇)說:「讓我們把所有領域都統一起來,你應當往我的規則添加權值,以產生新的代表方法,可以進行廣泛傳播。」王子說:「我們把我們的一個個後代稱作馬爾科夫邏輯網絡。」
你的頭有些暈。你走到陽台外,太陽已經在城市上空升起。你的目光從屋頂投向廣闊的鄉村。服務器之林向各個方向延伸,發出很低的嗡嗡聲,等待終極算法的到來。護衛沿著道路移動,從數據寶藏中取出金子。西邊很遠的地方,土地被信息之海佔據,散佈著船隻。你抬頭看終極算法的旗幟,現在可以清晰地看到在五角星中的銘文:
P=ew·n/Z
你想知道這到底有什麼含義。
馬爾科夫邏輯網絡
2003年,我開始思考如何將邏輯和概率統一起來,我的學生馬特·理查森也加入進來。一開始我們進展甚微,因為我們正試圖利用貝葉斯網絡來完成這件事,而它們的固定形式——變量的嚴格順序、依據父母對孩子進行的有條件分佈——與邏輯的靈活性不相容。但在平安夜的前一天,我意識到有一個好很多的辦法。如果我們切換到馬爾科夫網絡,可以利用任何邏輯公式作為馬爾科夫網絡特徵的模板,這樣就可以把邏輯和圖解模型統一起來了。看看我們怎麼做到的。
回想一下,馬爾科夫網絡是由特徵的加權和來定義的,這一點很像感知器。假設我們有一些人類的圖片,隨機拿起一張,然後依據它的特徵來算出概率,例如,「這個人有白頭髮」、「這個人年紀大了」、「這個人是一個婦女」等。在感知器中,我們利用一個門檻值來使這些特徵的加權和通過,以決定比如,這個人是不是你的祖母。在馬爾科夫網絡中,我們會做一點不一樣的事(至少乍一看是這樣的):我們對加權和進行指數化,將其變成因素的一個產物,而且該產物是從這批圖片中選定某張指定照片的概率,不管你的祖母在不在這張照片裡。如果你有許多老年人的照片,那麼特徵的權值就會上升;如果他們中的多數人都是男人,那麼「這個人是一個婦女」的權值就會下降。特徵可以是我們想要的任何東西,使馬爾科夫網絡變成一種很靈活的代表概率分佈的方法。
實際上,我撒謊了:因素的產物還不是概率,因為所有圖片出現的概率加起來一定等於1,而且不能保證所有圖片的因素產物都會這樣。我們需要使它們正常化,這就意味著通過它們所有的總和來劃分每個產物。那麼所有正規化產物的總和就可以保證是1,因為它僅僅是一個由自己劃分的數字。那麼一張照片的概率就是它的特點的權值和,經過了指數化和正規化。如果你回頭看五角星中的等式,你可能會微微懂得它的含義。P是一個概率,w是權值的一個向量,n是數字的向量,而它們的點積「·」被Z指數化和劃分,Z是所有產物的總和。如果我們讓第一個組成部分n為1,如果圖片的第一特徵不是真就是零等,那麼w·n也僅僅是我們一直以來談論的、特徵權值總和的速記方法。
因此根據馬爾科夫網絡,等式會給出圖片(或者隨便別的東西)的概率。但它比那更概括,因為它不僅僅是馬爾科夫網絡的等式,而是馬爾科夫邏輯網絡的等式,正如我們稱呼它的那樣。在馬爾科夫邏輯網絡(MLN)中,數字n不一定只是0或者1,而且它們不指代特徵——它們指代邏輯公式。在第八章的結尾部分,我們看到自己如何超越馬爾可夫網絡到達關聯模型,這些模型依據特徵模型而不只是模型來定義。「愛麗絲和鮑勃都患有流感」是特定於愛麗絲和鮑勃的特點。「X和Y都有流感」是一個特徵模型,可以和愛麗絲和鮑勃、愛麗絲和克裡斯等其他任意兩人實例化。特徵模型很有力量,因為它可以利用單個短表達式來概括幾十億甚至更多的特徵。但我們需要正式的語言來定義特徵模型,而我們有一個可輕易得到的語言——邏輯。
一個MLN只是一組邏輯公式及其權值。當應用到特定組的實體時,在這些實體可能狀態的基礎上,它定義了馬爾可夫網絡。例如,如果實體是愛麗絲和鮑勃,可能的狀態就是愛麗絲和鮑勃是朋友,愛麗絲患有流感,鮑勃也一樣。讓我們假設MLN有兩種公式:「每個人都患有流感」和「如果某些人患有流感,那麼他們的朋友也患有流感」。在標準邏輯中,這就是一對毫無用處的陳述:第一個陳述會排除所有陳述,即使是包含一個健康人的陳述也會被排除;而第二個就會變得多餘。但在MLN中,第一個公式僅僅意味著有一個特徵對於每個人X來說「X患有流感」,和公式一樣有相同的權值。如果人們可能有流感,公式就會有較高的權值,相應的特徵也會有。有很多健康人的陳述的可能性,會比有少量健康人的陳述要小,但也不是不可能。第二個公式,「某些人患有流感,而他們的朋友沒有」,這個陳述的可能性要比健康人和受感染人群朋友群不一樣的陳述的可能性要小。
這時可能你已經猜到n在終極算法中代表什麼:它的第一個組成部分是陳述中第一個公式真實實例的數量,第二個是第二個真實實例的數量,以此類推。如果我們在觀察一個有10個朋友的小組,而他們當中有7個人患有流感,那麼n的第一個組成部分就是7,以此類推(如果7/20,而不是7/10的朋友有流感,難道概率不應該不一樣嗎?是的,不一樣,因為有Z)。在極限情況下,如果我們讓所有權值趨於無窮大,馬爾可夫邏輯就會簡化為標準邏輯,因為違背公式的單個實例,會引起概率暴跌至0,使陳述變得不可能。在概率方面,當所有公式討論單個話題時,MLN會簡化為馬爾可夫網絡。因此馬爾可夫邏輯包含邏輯和馬爾可夫網絡兩個特殊案例,而這是我們過去尋找的統一效果。
掌握MLN意味著發現世界上真實存在的公式要比隨機因素預測出的頻率要高,並且需要弄明白那些公式的權值:公式使它們的預測概率與它們的觀察頻數相匹配。一旦我們掌握了MLN,就可以利用它來回答諸如「如果鮑勃和愛麗絲是朋友,而且愛麗絲患有流感,那麼鮑勃患有流感的概率是多少」此類問題。你猜怎麼著?原來概率是由S形曲線提供的,該曲線應用於特徵的加權和,這和多層感知器很相似。而包含長串規則的MLN可以表示深度神經網絡,在規則串中,每層會有一個鏈接。
當然,不要因為上文提到的簡單MLN預測了流感而被其欺騙。想像一下用MLN診斷和治癒癌症。MLN代表細胞狀態下的概率分佈。細胞的每個部分、每個細胞器、每條代謝途徑、每個基因及白細胞,在MLN中都是一個實體,而MLN的公式會對它們之間的差別進行編碼。我們可以詢問MLN:「這個細胞癌變了嗎?」然後利用不同的藥物對它進行調查,看看會發生什麼。我們還沒有這樣一個MLN,但在本章後面我會設想它會產生。
總的來說,我們到達的統一學習算法利用MLN作為表示方法,利用後驗概率作為評估函數,利用與梯度下降結合的基因搜索作為優化器。如果我們願意,可以輕易地利用其他準確度測量方法來代替後驗概率,或者利用爬山法來代替遺傳搜索。我們上升到一座高峰,現在我們可以享受風景了。但是,我不會那麼輕率地將這個學習算法稱作終極算法。一方面,布丁的味道好不好,吃了才知道,而且雖然過去10年這種算法(或者它的變化版本)已經成功應用於許多領域,但還是有許多領域沒有應用到它,因此還不清楚它的一般用途。另一方面,它還有一些重要的問題沒有解決。在看這些問題前,讓我們先看看它能做什麼。
從休謨到你的家用機器人
你可以從alchemy.cs.washington.edu這個網站下載我剛才描述的學習算法。用「煉金術」來為它命名是為了提醒我們,雖然它取得了成功,但機器學習仍然處於科學的煉金術階段。如果把它下載下來,你會看到它包含的東西要比我描述過的基礎算法多得多,但是它也缺少幾個我之前說的通用學習算法該有的東西,比如交叉。雖然如此,為了簡單,讓我們利用「煉金術」來指代我們的備用通用學習算法。
煉金術解決了休謨的原始問題,方法就是除了數據,要擁有其他的輸入東西:你的原始知識,依據一組邏輯公式,有還是沒有權值。公式可能不一致、不完整甚至完全錯誤,學習以及概率推理行為會關照那件事。關鍵點在於煉金術不必從零開始學習。實際上,我們甚至可以用煉金術來讓公式保持不變,然後只對權值進行學習。在這種情況下,給予煉金術恰當的公式可以將其變成玻爾茲曼機、貝葉斯網絡、實例學習算法以及許多別的模型。這解釋了為什麼雖然存在「天下沒有免費的午餐」的定理,但可以有通用學習算法。更確切地說,煉金術就像一台歸納圖靈機,我們可以對圖靈機進行編程,使其行動起來像非常有力量的或者受到極大限制的學習算法,這取決於我們。煉金術為機器學習提供統一物,就像互聯網為計算機網絡、關聯模型為數據庫,或者圖形用戶界面為日常應用提供統一物那樣。
當然,雖然你使用的煉金術沒有原始工具(而且你可以),這並不會讓它不包含知識。形式語言、評分函數、優化器會暗自對關於世界的猜想進行編碼。因此可以自然地問我們是否有比煉金術更通用的學習算法。當進化從第一個細胞開始它的長途之旅,一直到當今所有的生命形式時,進化會做出什麼假設?我認為有一個簡單的假設,所有其他的假設都會遵循這個假設:學習算法是世界的組成部分。這就意味著,學習算法作為一種實體系統,和它的環境一樣會遵循相同的規律,無論這個規律是什麼,我們都已經暗暗「知道」它,並做好準備去發現它。在接下來的部分中,我們會看到這個規律具體意味著什麼,以及如何在煉金術中體現它。就目前而言,我們注意到,它可能是我們能回答的休謨問題中最好的答案:一方面,假設學習算法是世界的組成部分是一種猜想——原則上是這麼說,因此它滿足休謨的宣言,認為學習僅適用於先驗知識;另一方面,這是一個多麼基礎而且難以反駁的猜想,也許這就是我們對於世界所需要的所有東西。
在另一個極端,知識工程師——機器學習最堅定的批評者——有好的理由來喜歡煉金術。不用基本模型結構或者幾次大概的猜想,煉金術可以導入一個大型、細緻的裝配知識基地(如果它可用)。因為概率規則與確定性規則相比,互動的方式更為豐富,所以手工編碼的知識在馬爾科夫邏輯中會更深入。馬爾科夫邏輯中的知識基地不一定要首尾一致,它們可以變得很大並容納許多不同的主要因素而不會崩潰——這是一個目前為止讓知識工程師迷惑的目標。
雖然如此,很多時候煉金術會解決機器學習中每個學派鑽研了很久的問題。讓我們反過來看看它們是什麼。
符號學家結合運算中不同碎片的知識,這和數學家結合公理來證明定理是一個道理。這和神經網絡和其他有固定結構的模型迥然不同。煉金術利用邏輯來完成這件事,正如符號學派所做的那樣,卻是一個迂迴曲折的過程。為了證明邏輯中的定理,你需要發現產生該定理的公理應用的唯一順序。因為煉金術從可能性的角度談到其實它要做得更多:找到公式的多重序列,引出定理或者它的否定面,然後對它們進行權衡,以計算出定理真實的概率。這樣它能推理的不僅與數學共性有關,還可以推理在一則新聞報道中的「總統」指的是不是「巴拉克·奧巴馬」,或者一封郵件該在哪個文件夾之下。符號學派的主算法——逆向演繹,假定新的邏輯規則,用於作為數據與預期結論之間的步驟。煉金術通過爬山法來介紹新的規則,以原始規則作為開始,與原始規則和數據相結合,構建使結果概率更大的規則。
關聯學派模型的靈感來源於大腦,S形曲線的網絡與神經元相對應,它們之間的加權關聯對應的是突觸。利用煉金術,如果兩個變量在某個公式中一起出現,那麼它們就被聯結在一起,考慮到近鄰,一個變量的概率就是一條S形曲線(我不會解釋為什麼,這是我們在前面部分看到的主算法的直接結果)。聯結學派的主算法是反向傳播,他們利用它來弄清楚哪個神經元負責哪些誤差,並根據它們的權值來進行調整。反向傳播是梯度下降的一種形式,煉金術用它來優化馬爾科夫邏輯網絡權值。
進化學派利用遺傳算法來模仿自然選擇。遺傳算法包含假設的「人口」,在每一代中,適應能力最強的會進行交叉和變異,以生產下一代。煉金術以加權公式的形式來維持假設的「人口」,在每一步中以不同的方法對它們進行改變,然後把那些最能提高數據(或者一些其他的評分函數)後驗概率的變量留下。如果人口是一個單一假設,這就簡化為爬山法了。當前煉金術的開源實施並不包含交叉,但這就是一個簡單的加法。進化學派的主算法是遺傳編程,應用交叉和突變於計算機程序上,以子集樹的形式表示出來。子集樹可以用一組邏輯規則來表示,Prolog編程語言就是這麼做的。在Prolog中,每個規則與一個子集對應,而它前面的規則是它稱呼的子集。因此我們可以將帶有交叉的煉金術當作利用Prolog相似編程語言的遺傳編程,這樣會有一個額外的優勢——規則可以是概率性的。
貝葉斯學派相信模擬不確定性是學習的關鍵,並利用形式表示方法如貝葉斯網絡和馬爾科夫網絡來工作。正如我們已經看到的那樣,馬爾科夫網絡是MLN的特殊類型。貝葉斯網絡利用MLN主算法也可以輕易表示出來,一個特徵對應一個變量及其起源的每個可能狀態,而相應條件概率的算法則作為它的權值(然後歸一化常數Z就便利地簡化為1,意味著我們可以忽略它)。貝葉斯的主算法是貝葉斯定理,執行的方法是利用概率推理算法,比如置信傳播和MCMC。正如你已經注意到的那樣,貝葉斯定理是主算法的特例,包含P=P(A∣B),Z=P(B),而特徵和權值對應P(A)和P(B∣A)。煉金術系統包含置信傳播和MCMC用於推理,推廣至處理加權邏輯公式。將概率推理用於對邏輯提供的證明路線上,煉金術為支持或者反對結局來權衡證據,並輸出結局的可能概率。這與符號學派利用的「單純功能」邏輯相反,該邏輯不是全有就是全無,因此當給定矛盾證據時,該邏輯就會崩潰。
類推學派的學習方法是假設有已知相似屬性的實體,也會有相似的未知屬性:擁有相似症狀的病人也會有相似的診斷,過去喜歡買某類書的讀者可能未來還會買同樣的書,等等。MLN可以代表具有像「擁有相同品位的讀者會買相同的書」公式的實體之間的相似性。愛麗絲和鮑勃買到的相同的書越多,他們越可能有相同的品位;(將相同的公式應用於相反方向中)如果鮑勃買一本書,愛麗絲也買這本書的概率就比較大。他們的相似性由他們有相同品位的概率來表示。為了使這一方法真正起作用,對於相同規則的不同實例,我們可以有不同的權值:如果愛麗絲和鮑勃都買了某本罕見的書,這包含的信息量也許會比他們購買暢銷書的信息量大,因此應該有更高的權值。在這種情況下,相似度由我們計算的屬性是離散的(買或者不買),但我們也可以在連續屬性之間表示相似度,就像兩座城市之間的距離一樣,方法就是讓MLN把這些相似性當作特點。如果評估函數是一個邊際風格評分函數,而不是後驗概率,結果就是支持向量機的概括版,也就是類推學派的主算法。我們的主學習算法面臨的更大挑戰是複製結構地圖,這是類比更強大的類型,可以從這個域(比如太陽系)推斷到另外一個域(原子)。我們可以通過學習公式來做到這一點,這些公式不會指代源域中的任何特定關係。例如,「抽煙的人的朋友也抽煙」講的是友誼和抽煙,但「相關的實體有相似的屬性」適用於任何關係和屬性。我們可以通過概括「朋友的朋友也抽煙,專家的同事也是專家」來掌握它,還有在社交網絡中其他這樣的模式,然後將其應用到諸如網頁之類的地方,包含像「有趣的網頁會鏈接到有趣的網頁」這樣的實例,或者應用於分子生物學中,包含像「與蛋白質調控互動的蛋白質也會調控基因」這樣的實例。我的小組的研究人員和其他人已經完成所有這些事,接著還會做更多。
煉金術也可以啟動我們在第八章提到的5種無監督學習。顯然,它會進行關係學習,實際上,這就是它很多已應用的地方。煉金術利用邏輯來代表實體之間的關係,以及用馬爾科夫網絡來使它們自己變得不確定。我們可以將煉金術變成強化學習算法,方法就是利用獎勵環繞它,並利用它來掌握每種狀態的值,這和傳統強化學習算法利用的方法一樣,比如神經網絡。我們可以在煉金術內部進行組塊,方法就是添加一種新的運算,這種運算會將一串串的規則變成單個規則(例如,「如果A那麼B,如果B那麼C,如果A那麼C」)。一個帶有單個未觀察到變量(且該變量與所有可觀察變量相聯結)的MLN會進行聚類(未觀察到變量是這樣一個變量:我們從未在數據中見過它的值,是「隱藏的」,可以這麼說,只能通過推斷得出)。包含一個以上未觀察到變量的MLN,通過由可觀察變量(數量更多)推斷那些變量(數量更少)的值的方法,來進行離散降維。煉金術也可以利用連續未觀察到變量來處理MLN,這些變量會在諸如主要成分分析、等距映射的過程中用到。因此,原則上說,煉金術可以做所有我們讓機器人羅比做的事,或者至少所有我們在本書中討論過的事。的確,我們已經利用煉金術來讓機器人掌握其所在環境的地圖,通過它的傳感器弄明白哪裡是牆、哪裡是門,以及它們的角度和距離等,這是製造稱職家用機器人的第一步。
最終,我們可以將煉金術變成一種元學習算法,比如通過將個體分類器編碼成MLN來進行堆疊,添加公式或者學習公式以將它們結合起來。這就是DAPRA在其個性化學習助手(PAL)項目中所做的。PAL是DARPA歷史上最大型的人工智能工程,也是Siri的祖先。PAL的目標是構建自動化秘書。它利用馬爾科夫邏輯來作為其支配一切的表示方法,將來自不同模塊的輸出融合到該做什麼的最終決定中。這也允許PAL的模塊通過追求統一意見來彼此互相學習。
目前煉金術最大的應用在於從網絡中學習語義網絡(或者谷歌所謂的知識圖譜)。一個語義網絡就是一組概念(就像行星與恆星)以及這些概念中的關係(行星環繞恆星)。煉金術會通過從網頁中提取的事實(例如,地球繞著太陽轉)來掌握100萬個以上這樣的模式。它會獨自發現諸如行星之類的概念。我們之前使用過的版本,比我在此已經描述過的基本版要先進,但基本思想是一樣的。各式各樣的研究已經利用煉金術或者他們自己的MLN執行工具來解決自然語言處理、計算機視覺、動作識別、社會網絡分析、分子生物學及其他許多領域中的問題。
儘管成功了,煉金術還是有一些明顯的不足之處:它還沒有真正擴展到大數據,而一些在機器學習領域沒有博士學位的人會發現它很難使用。因為這些問題,它還沒有準備就緒,讓我們看看能對它們做些什麼。
行星尺度機器學習
在計算機科學中,如果一個問題沒能得到有效解決,它就沒有真的得到解決。如果你不能在可用時間和記憶內完成一件事,那麼知道這件事怎麼做並沒有多大用處,因為在你處理MLN時,這些時間和記憶會消耗得很快。通常我們利用數百萬的變量和數十億的特徵來對MLN進行學習,但這並不像表面看起來的那麼大規模,因為變量的數量會隨著MLN中實體的數量迅速增長——如果你有一個包含1000人的社交網絡,你就已經擁有100萬對可能的朋友,以及10億個「朋友的朋友是朋友」公式的實例。
煉金術中的推理是邏輯與概率推理的結合。前者通過證明定理來完成,後者則通過置信傳播、MCMC以及我們在第六章中見過的其他方法來完成。我們將兩者結合至概率定理證明中,統一推理算法可以計算任意邏輯公式的概率,是當前煉金術系統的關鍵部分。但在計算法方面,它需要的很多。如果你的大腦利用概率定理證明,那麼一隻老虎會在你沒來得及想明白如何逃離時就把你吃掉,這就是馬爾科夫邏輯一般性的高昂代價。你的大腦在真實世界中已經進化,必須對額外的猜想進行編碼,這樣有利於它進行有效推理。在過去幾年中,我們已經開始弄清楚它們可能是什麼,並將其編碼入煉金術。
這個世界並不是由隨意雜亂的相互關係組成的,它有等級結構:星系、行星、大陸、國家、城市、社區、你的家、你、你的頭、你的鼻子、其頂部的細胞、它裡面的細胞器、分子、原子、亞原子粒子。那麼模擬世界的方法會用到MLN,也有等級結構。這是一個猜想的例子,學習算法和環境都相似。MLN不需要知道,基於假定,世界由哪些部分組成。煉金術要做的,就是假設世界有若干個組成部分,然後將這些部分找出來。這很像一個剛做好的書架,假設有若干書,但還不知道哪些書會放在書架上。等級結構有助於使推理更易於處理,因為世界的子部分更多的是會與同部分的子部分互動,比如,鄰居彼此之間的交流會多於與其他國家人民的交流,由同一個細胞產生的分子也會更多地與那個細胞的其他分子進行反應。
另外一個使學習和推理變得更容易的屬性,就是存在於世界的實體不會以任意形式出現。它們會分成不同的類別和子類別,來自同一等級的成員之間的相似性會大於來自不同等級成員之間的相似性。有生命的或者無生命的,動物或者植物,鳥類或者哺乳類,人類或者非人類,如果我們知道與當前問題相關的所有特質,就可以將所有這些特質以及可以節省很多時間的實體合在一起。像以前那樣,MLN不用知道基於假定的世界上的類別是什麼,它可以通過分級聚類來從數據中掌握這些類別。
世界包含各個部分,而每個部分又屬於不同類別,將這些部分和類別結合起來,這樣使煉金術中的推理變得易於處理所需要的東西就已經基本齊全。我們可以掌握世界的MLN,方法就是將其分解成若幹部分和子部分(這樣多數互動關係就存在於同一部分的子部分之間),然後將各個部分集合成類別和子類別。如果世界是一個樂高玩具,那麼我們將其分解為一塊塊「磚」,記住哪塊和哪塊相連,然後通過形狀和顏色來將「磚塊」集合起來。如果這個世界是維基百科,我們可以將它談論的實體抽取出來,將它們集合成類別,然後學習類別之間如何相互關聯。如果某人問我們:「阿諾德·施瓦辛格是動作明星嗎?」我們可以回答:「是的,因為他是明星,而且他在動作片裡。」漸漸地,我們能夠學習越來越大規模的MLN,直到去做我的一位谷歌朋友稱作「世界範圍的機器學習」的事:同時模擬世界上的每個人,數據會不斷流入,答案則不斷流出。
當然,如此規模的學習需要的不僅是直接執行我們見過的算法。例如,除這一點之外,單個處理器還不足夠,我們得在許多服務器上分配學習。工業和學術界的研究人員已經深入調查,例如,如何並行使用多台計算機來進行梯度下降,其中一個選擇就是在處理器之間劃分數據,另外一個就是劃分模型的參數。在每個步驟之後,我們將結果整合起來,然後重新分配工作。不管怎樣,在不讓交流成本壓倒你,或者不讓結果的質量受困擾的情況下完成這件事,做到這一點絕非易事。另外一個問題就是,如果你有無數數據串要輸入,那麼你在實現某些決定之前,不能等著看數據。一個解決辦法就是利用採樣原理:如果你想預測誰會贏得下一屆總統選舉,就不必問每個選民會投給誰,幾千個人的樣本已經足夠(如果你願意接受一點不確定)。訣竅就是把這個推廣到擁有幾百萬個參數的複雜模型中。但我們只能通過這樣的方法做到一點,即在每一步中盡量從數據流中舉例子,因為我們要十分肯定自己做了正確的決定,並且所有決定的不確定性保持在允許範圍內。利用這種方法,我們就可以在有限的時間內從無限數據中學到東西,就像我在一篇提議這種方法的論文中提及的那樣。
大數據流系統是塞西爾·德米爾機器學習的產品,擁有數千個服務器,而不是數千個附加設備。在最大型的項目中,只要把所有數據彙集起來、驗證數據、清除數據、將數據處理成學習算法能消化的形式,這樣做,建造金字塔就簡單得像在公園散步一樣。
歐洲的「未來信息和通信技術」項目旨在建造整個世界(真正含義即是字面意思)的模型。社會、政府、文化、技術、農業、疾病、全球經濟等不能落下一樣。這當然還不成熟,但它卻預示著未來要發生的事。同時,像這樣的項目可以幫助我們找到可擴展性的極限在哪裡,以及如何克服這些極限。
計算複雜性是一件事,人類複雜性是另外一件事。如果計算機就像白癡專家,那麼學習算法有時會遇到少年天才亂發脾氣的情況,這也是那些能征服他們的人類會收穫頗豐的原因之一。如果你知道以專業的手法調整控制旋鈕,直到到達恰當的位置,那麼魔法就會隨之而來,以一連串超越學習算法年份見解的形式出現。
而且,和德爾斐神諭並無兩樣的是,解釋學習算法的宣言本身需要大量的技能。雖然如此,如果轉錯手柄,學習算法可能會湧出一系列胡言亂語,或者在反抗中保持沉默。不幸的是,就這一點而言,煉金術並不比多數算法好。把你知道的用邏輯的形式寫下來、輸入數據、按下按鈕才是好玩的部分。當煉金術返回準確而有效的MLN時,你會去酒吧慶祝;當它不返回時——很多時候會出現的狀況——戰爭就開始了。問題存在於知識、學習、推理中嗎?一方面,因為學習和概率推理,簡單的MLN可以做複雜程序能做的事。另一方面,當它不起作用時,調試起來就困難很多。解決辦法就是讓它更加交互,有能力進行反省,並解釋它的推理。這就會讓我們向終極算法更加靠近一步。
醫生馬上來看你
治癒癌症的方法是一種能夠輸入癌症基因組,並輸出殺死癌細胞藥物的程序。我們現在可以想像,這樣的程序(就叫它「CanceRx」)會長什麼樣。儘管外表上看起來簡單,CanceRx是編出的程序中規模最大也是最複雜的程序,的確太大了,所以它只能在機器學習的輔助下建立。它的基礎是一個關於活細胞如何運轉的詳細模型,人體內的每種細胞都會有一個子類別,還有關於細胞如何互動、支配一切的模型。該模型以MLN或者與其相似的形式,將分子生物學的知識與來自DNA測序儀、微陣列,以及其他許多來源的大量數據結合起來。有些數據通過手動進行編程,但大部分是從生物醫學文獻中提取出來的。模型會不斷進化,並將新實驗的結果、數據來源、患者病歷合併起來。最後,它就掌握每種類型人體細胞中的每條路線、調節機制、化學反應,這就是人體分子生物學的總和。
CanceRx會將其大部分時間用於搜索包含備選藥物的模型。考慮到新藥,該模型會預測藥物對癌細胞和正常細胞的效果。當愛麗絲被診斷為癌症時,CanceRx會利用她的正常細胞和腫瘤來將它的模型實例化,並嘗試所有可能的藥物,直到它找到一種能殺死癌細胞而又不傷害健康細胞的藥物。如果它找不到有效藥物或者有效藥物組合,那麼它就會著手研發一種會治癒癌症的藥,也許會利用爬山法或者交叉法來讓它從現有的藥物中發展起來。它會在研究中的每一步中,在模型上嘗試備選藥物。如果藥物抑制了癌症,但仍然有一些有害的副作用,CanceRx會嘗試調整它以擺脫副作用。在癌症變異前,模型就能預測可能的變異,CanceRx就會開出那些能在中途扼殺癌變異細胞的藥物。在人性與癌症這場象棋遊戲中,CanceRx將是將軍。
請注意機器學習不會獨自把CanceRx給我們。這不像我們有一個巨大的分子生物學數據庫整裝待發,將這個數據庫輸入終極算法,彈出來的是活細胞的完美模型。在多次交互作用下,CanceRx可能是無數生物學家、腫瘤醫生、數據科學家進行世界範圍內合作的最終結果。然而,最重要的是,CanceRx會在醫生和醫院的協助下,從幾百萬個癌症病人中整合數據。沒有數據,我們就無法治癒癌症;有了它,就能治癒癌症。為整個不斷壯大的數據庫做貢獻,這不僅是每個病人的利益,還是它的倫理責任。在CanceRx的世界中,離散的臨床實驗是過去的事情。CanceRx提出的新治療方法也正在繼續被推出,如果這些治療方法起作用,則會用到更廣範圍的病人身上。在經過改善的良性循環中,成功和失敗的經歷都會為CanceRx的學習提供寶貴的數據。如果你以某種方式看待它,機器學習可能只是CanceRx工程的一小部分,僅次於數據收集和人類貢獻。但如果以別的方式看待它,機器學習就是整個企業的關鍵。沒有它,我們只能掌握癌症生物學的零碎知識,散落在數千個數據庫和數百萬篇科學文章中,每個醫生只會注意一小部分。將所有這些知識集中成一個連貫整體,這超出了不受協助的人類的能力,無論人類多麼聰明,只有機器學習才能做到這件事。因為每種癌症都不一樣,它讓機器學習找到通用模式。而且因為單個組織會產生幾十億個數據點,這就需要機器學習來弄明白能為每個新病人做點什麼。
現在人們已經在努力建造最終會成為CanceRx的東西。在系統生物學的新領域中的研究員會模擬整個代謝網絡,而非個體基因和蛋白質。位於斯坦福的一個團隊已經構建了整個細胞的模型。全球基因組學與健康聯盟推動數據在研究員和腫瘤學家之間的分享,著眼於大規模分析。癌症聯盟會(Cancer Commons.org)收集癌症模型,讓病人集中他們的病歷,然後從相似例子中學習。基礎醫學(Foundation Medicine)查明病人腫瘤細胞中的變異,然後開出最合適的藥物。10年前,人們不知道癌症是否可以或者如何被治癒,現在我們就能看到如何做到這一點。路還很長,但我們已經找到路了。