2007年,得克薩斯州州長裡克·佩裡簽署了一項決議,要求得克薩斯州所有12歲的女孩必須接種人乳頭狀瘤病毒疫苗(HPV),這種瘤會導致女性患宮頸癌。在2012年的共和黨黨內初選中,候選人之一的米歇爾·巴赫曼曾借這一事件攻擊了裡克·佩裡,她聲稱一個女士告訴她:「我的女兒接種了那個疫苗,注射後她經受了智力發育遲緩的折磨」。
巴赫曼的邏輯有什麼問題嗎?或者說她是在引導我們推斷——HPV疫苗引起了智力發育遲緩嗎?讓我們來分析一下。
我們需要想想巴克曼用以做證據的樣本,這是美國所有注射了該疫苗的12歲女孩中的一例。這個有關智力發育遲緩的例子中只包含極少的樣本(很低的樣本量),要用它來證明注射過疫苗的女孩面臨智力發育遲緩的風險是極其缺乏說服力的。
事實上,在女孩們注射疫苗之後,工作人員還對被隨機選出的注射者和被注射者進行了好幾次嚴格的隨機對照實驗。這些實驗都包括了非常大的樣本量。這些實驗的結果並沒有顯示出,注射過疫苗的女孩比未注射過的女孩面臨更高的智力發育遲緩的風險。
巴赫曼的樣本裡只包含一個注射過疫苗的12歲女孩——這是一種「恰好是他」似的統計。巴赫曼選來的樣本頂多是偶然的,而非隨機的。樣本選擇過程越接近隨機選擇的黃金標準——人群中的所有人被選中的概率是一樣的,選擇結果越可信。如果我們不知道一個樣本是否是隨機被選出的,那麼我們對該樣本進行的測量就會在某種未知的情形下發生偏差。
實際上,巴赫曼給出的樣本甚至連一個偶然的樣本都比不上。假設巴赫曼說的是實情,那麼她本身便有很強的動機想把這個案例公之於眾。而她可能沒有說出實情,或者給她提供消息的人沒說出真相,即提供消息的人說了假話。這個人可能十分確信自己告訴巴赫曼的事實。如果她的女兒注射了疫苗,而之後被診斷出了智力發育遲緩,那麼這位母親很有可能會犯事後歸因的錯誤:A之後發生了B,所以A是產生B的原因。事實上,事件A先於事件B發生,並不一定代表事件A導致了事件B。不過對我而言,巴赫曼的這個例子還不是最糟糕的「恰好是他」的統計謬誤。
我最喜歡的一個結合了「恰好是他」統計偏差的事後歸因謬誤例子是從一個朋友那裡聽來的,而他則是聽到了兩位老人的對話。第一個老人說:「我的醫生告訴我,我必須戒煙,否則我會因此而死。」第二個老人說:「不!不要戒!我有兩個朋友都聽了醫生的話戒了煙,然後他倆都在幾個月之內就死了。」
樣本和總體
回想第1章裡提到的醫院問題的推理。較小的醫院裡男孩出生比例超過60%的天數超過了較大的醫院。唯有大數定律能解釋這個問題:隨著樣本容量的增加,樣本的值(例如均值或比例)就越接近總體對應的值。
在總體的規模達到極端的情況下,很容易就能看出大數定律的效果。假設某一天某家醫院有10個嬰兒出生。那麼有多大概率這其中有60%或以上的嬰兒是男嬰呢?答案當然是,很有可能。我們當然不會懷疑,如果拋10次硬幣,有可能6次正面朝上。假設某一天另一家醫院有200個嬰兒出生。有多大概率男女嬰比例偏離正常值呢?答案很明顯,幾乎沒有可能會偏離50%太遠。這就像是拋了200次硬幣,你期待有120次或更多的時候硬幣正面朝上,而不是100次。
順便提一句,我注意到樣本統計值(均值、中位數、標準差等)的準確性與總體的規模是無關的。在美國,大多數對於大選的全國性調查僅包括1000個左右的被調查者,而調查者稱調查結果與實際結果的偏差不超過±3%。一個1000人的樣本就統計出了1億總人口對某一位總統候選人的確切的支持率,結果幾乎和1萬人的樣本一致。所以,當你支持的候選人的支持率領先對手8%的時候,別在意其他候選人的競選代理人對民意調查結果的蔑視,他們宣稱實際投票者有上百萬,而參與民調的只有區區1000人。除非那些參與民調的人在總體中真的是十分不具有代表性(或者說極其小眾),只有這樣,那些你不支持的候選人才會最終勝利。而這就要引出我們的下一個話題,樣本偏差。
只有當選取的樣本沒有偏差時,大數定律才是成立的。如果選取樣本時允許出現一定概率的樣本值錯誤的話,那麼統計的結果可能會有偏差。如果你想調查一家工廠裡有多少工人希望採取彈性工作制,而你的樣本裡只包含了男性工人或是在工廠的自助餐廳工作的工人,那麼你得到的結果將會和以全廠所有工人為樣本得到的結果有巨大差異,最終得到一個希望採取彈性工作制的工人比例的錯誤估算值。如果選取的樣本本身就有偏差,那麼這個樣本規模越大,你就越有可能得到錯誤統計結果。
這裡需要指出的是,實際上,全美民意調查並不是從總人口中隨機取樣的。如果是隨機的,那麼美國的所有投票者都應該有均等的機會成為被調查對象,但真實的調查並非如此,調查者是冒著會出現嚴重偏差的風險而進行取樣的。美國歷史上第一次對總統競選進行的全國民意調查是由現今已不再發行的《文學文摘》雜誌組織進行的。該調查結果顯示,富蘭克林·羅斯福將輸掉1936年的總統大選,然而最終他以壓倒性優勢獲勝。是《文學文摘》的問題嗎?這次調查是通過電話進行的——而當時只有家境較好的人家(這樣的富裕人家多半是屬於或支持共和黨的)才會安裝電話。
而在2012年的美國大選中,相似的樣本源偏差再次發生在一些民意調查中。拉斯姆森調查公司在電話調查中並沒有通過撥打手機進行調查,他們因此忽略了一點:年輕人大多只使用手機,並且傾向於支持民主黨。拉斯姆森公司因為系統性偏差,沒有同時在固定電話和手機用戶中抽樣,最終高估了來自共和黨的羅姆尼的支持率。
過去,只要人們接聽調查電話或是開門接受上門調查員的訪問,調查者就能得到一個近乎隨機採集的樣本。而今,民意調查的準確性在一定程度上依賴於調查者得到的數據和他們如何確定樣本的直覺——衡量一個樣本需要綜合各類信息:被訪者最終會參與投票的概率、其黨派身份、性別、年齡、他們所屬的社團成員、信仰的教派信徒在過去的投票情況,以及其他各種零碎古怪的信息。
找到真分數(true score)
請思考下面一些問題。
X大學設立了一個著名的音樂劇項目。該項目只為一小批具有非凡音樂潛質的高中畢業生提供獎學金。簡是這個項目的負責人,她有一些朋友是當地高中的戲劇課老師。一天下午,她去斯普林菲爾德高中考察一個學生的情況,這個孩子是由其戲劇課老師強力推薦的,據說是一個十分優秀的年輕女演員。簡觀看了一出由羅傑斯與漢默斯坦創作的音樂劇的綵排,那個女孩子在劇中擔任主角。結果,她說錯了好幾句台詞,看上去她對角色的把握也不好,表現得像是幾乎沒什麼舞台表演經驗。簡告訴她的同事,她現在十分懷疑她的朋友的判斷。這是一個明智的結論嗎?
喬是Y大學橄欖球隊的球探,他去美國各地的中學練習賽上觀看了比賽,考察那些由教練推薦給他的有潛質的年輕人。一天下午,他也來到了斯普林菲爾德高中考察一個有著出色得分紀錄的四分衛。這個孩子有著出眾的技術統計記錄,並且得到了教練的高度評價。在練習中,這個四分衛傳錯了幾次球,還投丟了幾回,總共也沒得到多少分。這位球探表示這個四分衛被高估了,並且建議Y大學不再考慮將他吸納進來。這是一個明智的建議嗎?
如果你認為簡是明智的,而喬不是,那麼只能說你比較瞭解體育競賽的情況,卻對戲劇演出知之甚少。如果你的結論正相反,則說明你熟悉戲劇演出而對體育競賽不太瞭解。
我發現,那些不太瞭解體育的人往往認為喬可能是對的,即那個四分衛或許並沒有那麼有天賦;而瞭解體育競賽的人更傾向於認為喬下的結論可能太過草率。他們認為,喬用於判斷那個四分衛的表現的(極其小的)樣本更可能是一種極端的情況,而給喬推薦那個孩子的教練的評價可能更接近實際情況。
那些不太瞭解戲劇表演的人可能會說那個女孩或許沒有那麼出色,然而瞭解戲劇的人會認為簡對女孩的判斷有些輕率。在其他條件都一樣的情況下,你對某個特定領域瞭解得越多,你就更可能成功運用統計學概念來考慮相關問題。在這個例子中,重要的概念便是大數定律。
為什麼這與大數定律有關呢?一個四分衛在一個或更多賽季的表現可以被看作評判其技術的可信依據。如果他的教練堅持認為他的確出色,那麼我們有大量證據——眾多技術統計數據——推斷喬考察的這位球員真的特別優秀,喬自己的證據——一天中的一場比賽的表現與之相比就顯得太不可信了。
一個球員自身表現的可變性,甚至是一支球隊表現的可變性,就像一句老話形容的那樣,在某一個星期日,美國全國橄欖球聯盟中的任何一支球隊都可以擊敗其他任何一支球隊。這當然不是說所有球隊的水平完全一樣,這只是表明你需要一個相當大的樣本量來準確評斷不同球隊的水平。
同樣的推斷邏輯也可以應用於那位戲劇項目負責人的判斷。如果有好幾位瞭解那位女演員的人都表示她有很高的才華,那麼這位負責人就要對自己的判斷三思。我發現很少有人意識到這一點,除了那些有一些戲劇表演經驗或對表演領域十分熟悉的人。喜劇演員史蒂夫·馬丁在自傳中曾提到,幾乎所有喜劇演員都有奉獻出偉大演出的時刻。那些成功者不過是能時時保持良好水平以上的人。
用統計學術語來講,球探和音樂劇項目負責人試圖尋找的是他們考察的候選人的「真分數」。考察結果包括真分數和偏誤。這個公式適用於幾乎所有類型的測量項目,無論是人的身高,還是某一地的氣溫,都是如此。有兩種途徑可以提高分數的準確性。一種是應用更好的觀測法——更好的碼尺或是溫度計。另一種是「消除」你在測量過程中可能出現的各種偏誤,這可以用大數定律或是求取平均值來解決。大數定律這樣發揮作用:你進行的測量越多,便會越接近於真分數。
訪談錯覺
即使我們對一些領域有豐富的知識,也掌握了大量統計學原理,但仍有可能忘記大數定律的變化性和相關性。密歇根大學心理系對其頂尖的申請人進行面試,以做出最終的錄取決定。我的同事對於和每個候選人進行20~30分鐘的面試十分看重。「我認為她不合適。她似乎對我們討論的課題沒有太深的見地。」「他看上去十分合適。他談到了他出色的榮譽論文,而且清晰地表達了他對如何做學術研究的理解。」
這裡的問題是,我們究竟該依據什麼來評判一個人,應該讓他在一段很短時間內的表現成為主要依據嗎?還是應該綜合評估其各項條件:大學裡的平均績點,它總結了一個學生4年中在30門或更多課程中的表現;研究生入學考試(GRE)成績,它從一個側面反映了一個學生12年的學習成果和綜合知識能力;推薦信,這通常會基於這個學生與推薦人長期的接觸和交流。實際上,大學平均績點在很大程度上能預測出一個學生在研究生院的表現(就像你在下一章節中會看到的,兩者的相關性至少能達到0.3),研究生入學考試分數同樣重要。這兩項標準是相互獨立的,因此同時使用這兩個標準進行評估比單獨使用其中一項要更有效。而加上推薦信之後,對學生評估的準確率就更高了。
然而,半小時的面試結果與一個學生在本科或研究生階段的表現僅僅存在不到0.1的相關關係,同樣的情況也可見於陸軍軍官、商務人士、醫學院學生、和平隊志願者和其他各類面試中。那是一種相當不準確的預測,不會比投硬幣預測好太多。其實人們如果只是以面試該有的價值來看待它,那麼結果並不會太糟,只要不將它當作決定性因素就好。然而人們總是在過於看重面試的誤區中讓自己逐漸偏離準確結果。
實際上,人們過度看重面試的價值,以至很容易最終事與願違。他們認為,面試表現比平均績點高更有說服力,面試會比基於和候選人長期接觸而產生的推薦信更能預測候選人在美國和平隊的表現。
對於「面試」,我們應當明白:如果對於一個學校或一份工作的候選人來說,可以在他的申請材料中獲取重要的、有價值的信息,那麼最好不要再面試他了。如果你能夠以面試真正具有的並不那麼重要的價值來衡量它,那麼它就不可能真的影響你的判斷。然而,我們幾乎無法抑制自己要過度看重面試的傾向,因為我們對於通過直接觀察一個人而瞭解其能力和品性有著不切實際的自信。
這就像是我們將面試中對某個人的印象看作對他進行了全息攝影的結果——只有一些微小的、模糊的結果是可以確定的,但是那並不是一個人完整的樣子。我們應當把面試看作對一個人進行瞭解的微小的、碎片化的,甚至可能是有所偏差的側面。想想盲人摸象的故事,你應該不想成為其中的一個盲人吧。
面試錯覺和基本歸因謬誤同出一源,它們都是我們將所獲取的不完整的信息誇大的結果。進一步來說,基本歸因謬誤就是我們高估了一些確定性的性格因素而忽視了環境因素,這會讓我們對於面試中獲得的信息產生懷疑。更好地理解大數定律有助於我們避免更多的基本歸因謬誤,並減少面試錯覺。
我希望我能說自己對於面試有效性的知識會常常讓我質疑自己基於面試而得出的結論。然而,效果真的有限。那種我自以為有價值的知識導致錯覺的力量十分強大。我不得不嚴肅提醒自己不要太看重面試——或者其他通過短時間接觸就下結論的情形。這一點在我能從其他途徑(他人在長期接觸中對某人形成的印象、學術記錄或者工作成就)獲得更充分信息時尤其重要。
當然,我會很容易就記住你在面試中表現出的非常有限的判斷力!
離散與回歸
我有一個朋友凱瑟琳,她的工作是為醫院進行管理實務的咨詢。她十分熱愛自己的工作,一部分原因是她可以借工作之便去各地旅行,結識新的朋友。她對美食情有獨鍾,總會去那些受到高度認可的餐廳體驗。然而,她常常抱怨,當她第二次再去那些起初覺得好的餐廳時,卻再也品嚐不到當日的美味了。你覺得原因是什麼呢?
如果你說「可能是廚師極大地改變了烹飪方法」,或者猜測「可能是她的期待太高了,以至實際情況會讓她失望」,那麼,你就忽略了一些重要的統計學的因素。
以一種統計學的視角來看待這個問題,那麼你首先應當想,凱瑟琳在任何一個場合、任何一家餐廳吃到特別美味的食物總存在一種偶然因素。當一個人在不同情形下在同一家餐廳吃飯,或是一群食客於某一個時間在某家特定的餐廳吃飯,人們對於好吃與否的評斷標準都會存在差異。凱瑟琳在某家餐廳吃到的第一頓飯可能只是馬馬虎虎(甚至更糟糕),也可能極其美味。這種變化便是我們評斷食物質量的變量。
任何連續的變量(會存在從一個極端到另一個極端的連續完整值域,比如身高),和與它相反的非連續變量(比如性別或是政治傾向)相比,都會有一個均值和一個圍繞均值分佈的值域。基於這一點,我們就不難理解凱瑟琳總會感到失望:有時她第二次去同一家餐廳的體驗會比第一次差,這幾乎是必然的(當然有時候第二次的體驗會好於第一次)。
但是我們還要進一步分析。我們可以預期,凱瑟琳對一家之前有著不錯印象的餐廳的看法會改變,認為它不如從前了。這是因為,越是接近一個給定值的平均值,那麼它就越會顯得不出眾。一個值距離均值越遠,則那個值越珍貴。因此,如果她在場合1中吃到了美味的一餐,那下一餐就可能就沒有那麼美味(在值域上處於極端位置)了。這對於所有符合正態分佈定義的變量都是成立的,該曲線被稱作「鍾形曲線」,如下圖所示。
正態分佈是一種數學上的抽像表示,但是其形態時常驚人地近似於連續變量的分佈——每週由不同母雞下的雞蛋數量,每週製造的汽車變速器中出現的差錯數量,人們的智商分數分佈幾乎都近似於正態分佈。沒有人知道這究竟是為什麼,但這的確是事實。
有許多種方式可用於描述在均值周圍分佈的樣本的離散情況。其中一種是值域,即在可見樣本範圍內用最高值減去最低值。一種更有用的描述離散情況的工具是以均值為基準而產生的平均離差。如果凱瑟琳在不同城市的餐廳品嚐的第一頓美餐的平均質量是「非常好」,而均值的平均離差分別為「很高」(高的一邊)和「一般好」(低的一邊),那麼我們會說針對凱瑟琳第一頓美餐的質量均值而產生的平均離差(離散程度)不算非常大。如果平均離差的範圍是從「極好」到「極普通」,那麼我們認為離散程度很大。
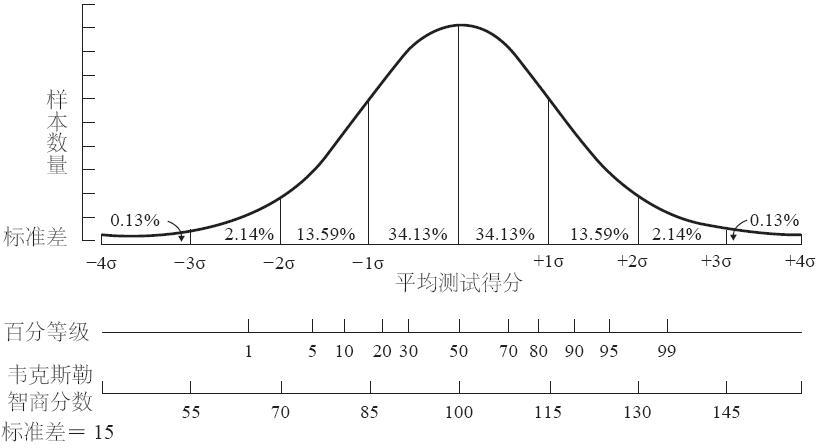
智商得分的正態分佈圖,均值為100,圖中展示了對應的標準差和百分等級
當然,還有相當多的有效測量離散情況的方法,我們可以借此計算任何變量,它們可以被賦予連續的數值。這就是標準差(或者稱作SD,可以用希臘字母δ表示)。標準差應當是數據集中的每一個數據與均值的離差平方的算術平均數的平方根。從概念上講,它不同於平均離差,但是標準差有一些極其有用的屬性。
圖中的正態曲線被標準差劃分成幾部分。大約有68%的值分佈在距離均值正負一個標準差的值域內。以智商測試分數為例。大多數智商測試是以具體分數為結果的,因此平均值常被設定為100,而標準差為15。若一個人的智商測試得分為115,則他比平均得分高出了一個標準差。均值和比均值高一個標準差的值的差距是相當大的。一個智商測試得分為115的人被認為可以完成大學學業,甚至能完成一些研究生層次的學業。社會中的典型職業分為專業類的、管理類的和技術類的。一個智商測試得分為100的人大多只會完成一些社區大學或大學預科課程的學業,有時只完成高中課程要求就足夠了,而他們未來的職業主要是商店經營者、職員或者商人。
另一個有關標準差的有效事實是百分位數值與標準差之間的關係。找到比均值高一個標準差的點,大約有83%的樣本值都比該點表示的值要小(在圖中對應區域為自「+1δ」點向左)。正巧在比均值高一個標準差的那個點上的值在整個正態分佈中的排位為前16%。剩下的16%的樣本值高於這84%的值。有幾乎98%的樣本值落在比均值高兩個標準差的點的左側(即小於「均值+2δ」)。正好落在「均值+2δ」點上的值在整個值域中的排位為前2%,即只有剩下的2%的值大於它。幾乎所有的值都會落在距離均值正負三個標準差的區間裡。
瞭解了標準差與百分等級之間的關係可以幫助我們判斷生活中遇到的大部分連續變量的情況。例如,標準差常被用作金融領域的一個測量指標。一項投資的收益率的標準差被用於測量投資的波動性。如果一隻特定的股票在過去10年中的平均收益率為4%,其標準差為3%,這意味著,你能做出的最接近實際的猜測為:在未來,在68%的時間當中,收益率會是1%~7%;在96%的時間當中,收益率會是–2%~10%。這種情況會很穩定。你不會因此暴富,但也不大可能因為股票暴跌而貧民窟。如果標準差為8%,那麼在68%的時間當中收益率會是–4%~12%。你可能會因為這只股票大賺一筆。有16%的時間裡你將會拿到12%以上的收益率。另一方面,有16%的時間你的損失也會達到4%以上。這是很容易發生的。有2%的時間你的損失可能會達到12%以上,有2%的時間你的收益又會達到20%以上。你可能會突然間賺大錢,也可能窮得連襯衫也穿不起。
所謂的價值型股票是那些在收益和損失的變動性上都很低的股票。它們可能每年只需你付出2%、3%或4%的股息,既不會在牛市時上漲得太多,也不會在熊市時下跌得過多。所謂的增長型股票則是其收益之間存在很大標準差的股票,即同時具有股價飆升的潛力和股價暴跌的風險。
金融顧問一般會建議年輕的投資者選擇增長型股票,並且在熊市和牛市時都堅持不拋售,因為在較長時間段內增長型股票總是能化險為夷,最終增長。而對於年長的投資者,顧問們則建議他們盡量購入價值型股票,這樣就避免了在正逢退休之時被熊市套牢。
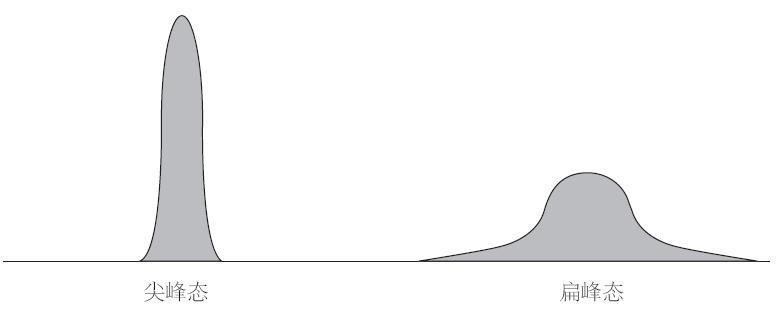
有趣的是,你剛才讀到的各類正態分佈曲線都有其獨特的形狀,只有時候會像「鍾形曲線」。曲線的峰態(凸出的部分)形狀迥異。尖峰態曲線(狹窄型)看上去像20世紀30年代漫畫書上的火箭艙體,有著高峰頂和較短的尾部。扁峰態曲線(寬闊的)則像是一條吞下了大象而腹部鼓起的蟒蛇,它有著低峰頂和較長的尾部。然而,無論是哪種形狀的曲線,只要是符合正態分佈,就會有68%的樣本值落在距均值正負一個標準差的區域裡。
現在讓我們再回到凱瑟琳的問題上,為什麼她總會對自己開始評價甚高的餐廳的美食感到失望呢?我們已經明白,她對餐廳中的食物的具體評價是不斷變化的:比如從「極其厭惡」(1%的排位)到「極其喜愛」(99%的排位)。假設凱瑟琳吃了一頓飯,認為它在自己的評價體系中的排位達到95%或者更高,即比她吃過的94%的飯都美味。現在,請大家就自己的吃飯經歷問自己以下問題:是否認為有很大的可能性,所有你第一次吃到的餐飯都會是特別美味的,或者其中只有一些是特別美味的?如果你認為自己不會期待所有的飯都會特別美味,那麼對於第二頓飯的期待值就至少會比極其美味的第一頓飯低一點兒。
有關凱瑟琳的第二頓飯的體驗可以被看作樣本向均值回歸的一個範例。如果人對於飯的感受(喜愛程度)呈正態分佈,極端值幾乎不存在,因此緊跟著極端值的某一次特定感受會低於極端值。這樣,最極端的情況就往低於極端的方向上回歸了。
回歸效應在日常生活中隨處可見。為什麼今年的棒球新人總是在來年表現得令人失望?因為,新人在第一年的表現是偏離其真分數的離散值,第二年他別無選擇,只會表現得遜色。為什麼在第一年增值超越其他股票的股票常在第二年表現得平庸很多,甚至更糟糕?原因還是「回歸」。為什麼在三年級表現最差的孩子在下一年反而表現得好了一些?依然是「回歸」。以上這些例子並不是說事物的走勢只有回歸這一種。均值的分佈並不是一個黑洞,能把所有的極端值都吞沒。還有其他一些因素在同時發揮作用,讓事物發展得更好或者更糟。雖然我們還不知道形成正態分佈的確切原因,但是我們需要明白,極端值之下總是有不那麼極端的值跟隨著,因為在綜合因素的作用下,極端值不會一直維持原狀。今年的棒球新人恰好有一位發揮得異常出色的教練來調教他;在今年的一系列比賽中,這位新人遇到的對手都相對較弱;他在今年正好和自己心愛的女孩訂婚了;他的身體健康狀態堪稱完美;他沒有受到任何傷病的困擾,等等。而在下一年,他因為肘部受傷而缺席了好幾場比賽;那位優秀的教練去了其他球隊;他的家人患上了嚴重的疾病,等等。生活中總是有各種不可預知的事情發生。
下面有兩個與回歸原則相關的問題(可能會令人驚訝):第一,一個年齡在25~60歲的美國人在某一年成為全美收入最高的1%的人中的一員的概率是多少?第二,一個人連續10年成為全美收入最高的1%的群體中的一員的概率是多少?
你可能無法想像,在美國,一個人成為收入最高的1%的群體中的一員的概率為11%,而一個人連續10年躋身該群體的概率為6‰。這還只是某一年的情況。這些概率數字變化令人震驚,因為我們不會自發地想到,像收入這種事情的變化性會這麼高,並且易受到回歸效應影響。但是,個人收入在多年中的分佈情況也有很大變動性(尤其是收入分佈的高點上)。極端收入在人口總體中出現得極少。而正是由於它們極端,所以它們不太可能會反覆出現。因此,那些令人討厭的1%的最高收入群體中的大部分人其實都在走下坡路,這樣你可能會善待他們一些!
同樣類型的數據也適用於低收入群體。超過50%的美國人在一生中至少會有一次變得貧窮,或者進入類似的狀態。相反,並沒有那麼多人會在貧困中度過一生。一直靠領取救濟金度日的人也極少。那些一度需要依賴社會保障生活的群體中的絕大部分人只會在幾年中是這種狀態。說到這裡,你也許要對這些生活困頓的人多一點兒好感了。
我們可能因為不會利用「向均值回歸」的框架分析事情而犯下許多嚴重的錯誤。心理學家丹尼爾·卡尼曼曾告訴一群以色列飛行教官,如果想改變一個人的行為傾向,那麼讚揚比批評有效得多。有一位教官反駁卡尼曼,他說讚揚一個飛行員差勁的演習行動會使他表現得更糟糕,相反,訓斥這個表現差勁的飛行員會讓他在下次演習中有所提升。然而,這位教官忽略了新手飛行員的發揮是不穩定的,在一次完美的飛行訓練之後,他的表現會有「向均值回歸」的趨勢,或者甚至會有更糟糕的表現。從概率的角度來看,在一次上佳表現之後,下次頂多可以期待他會有接近於平均值的表現;在一次糟糕的表現之後,則可以期待下次會好一些。
如果教官建立了表現是連續變量的概念,即一次極端值之後只可能出現接近極端值的狀況,那麼他多半只會看到他的學生下一次的表現更糟糕。他必須強化積極方面,以求學生有好於平均水平的表現,讓自己成為一個更好的導師。
飛行教官所犯的錯誤會因為我們都有的一把認知的雙刃劍而變得更嚴重。我們都是卓越的因果關係製造者。如果存在一個結果,我們幾乎都能找到解釋。
隨著時間推進,我們由觀察到的不同結果,都能很容易地給出因果解釋。然而大多數情況下,其實事情發展並沒有我們強加的這種因果——它只是隨機發生的。當我們已經習慣於看到一件事發生之後接連會發生另一件事時,這種強加因果的傾向就越發強烈。看到這種關聯我們幾乎會自發地進行因果解釋。如果我們能對這種進行因果解釋的行為保持警惕,那麼我們將會獲益匪淺。但是,這裡仍有兩個問題:第一,解釋來得太容易了,如果我們能意識到自己製造這種因果關聯有多麼草率,我們就會對它不那麼相信了;第二,在大多數情況下,如果我們對隨機性的概念有更深的瞭解的話,因果解釋就會顯得很不恰當,甚至我們都不會做出這樣的解釋。
讓我們再舉幾個應用回歸原理的例子。
如果一個孩子的母親的智商是140,其父親的智商是120,那麼你認為這個孩子的智商最有可能是多少?
160 155 150 145 140 135 130 125 120 115 110 105 100
精神治療師會對許多病人提及「前恭後敬效應」(hello/goodbye effect)。對於病人講述病情而言,治療開始前,他們的實際病情沒有他們說的那麼糟,而治療結束後,他們的實際病情也沒有他們說的那麼好,這是為什麼?
如果你說這個孩子的智商——父母兩人一方智商為140,另一方為120——會達到140或更高,那麼你並沒有考慮向均值回歸的現象。120的智商是高於常人平均水平的,而140也是高過平均值的。除非你認為父母的智商完全決定了孩子的智商,否則你就得預測這個孩子的智商水平會低於父母智商的平均值。因為父母智商平均值和孩子的智商的相關性為0.50(我想你可能不知道這一點),因此孩子的智商值應該為父母智商平均值和全部人口智商平均值的中間值,即115。超級聰明的父母生出的孩子也僅僅是一般聰明而已。不過,超級聰明的孩子的父母的智商也可能只達到一般水平。回歸是雙向發揮作用的。
對於「前恭後敬效應」的通常解釋是,病人為了尋求救治會故意表現出糟糕的狀態,而在治療結束時則想迎合治療師。無論這種解釋的真實性如何,我們都會看到病人在治療結束時的身體狀態要好於治療開始時,因為他們在治療過程中的情緒比平時要糟糕,並且僅僅是隨時間流逝,他們的狀態也會向均值回歸。你可能以為「前恭後敬效應」在有些治療中不會出現,而事實上,所有類型的醫生大體上都經歷過這樣的時候:一個病人的身體狀況無論怎樣都會隨時間推移而改善,除非病灶不斷發展。這樣看來,任何一種干預治療都會顯得相當有效。「我喝了一些蒲公英湯,我的感冒徹底好了。」「我的妻子剛得流感時就喝了龍舌蘭根搾出的汁,所以她感冒的時間比我少了一半。」那種「恰好是他」的統計加上事後顛倒因果的解釋之法促生了大量萬靈藥的製造商。他們信誓旦旦地宣稱,相當多的病人在服用他們的藥品之後身體狀況好轉了。
不過,關於回歸這一概念,我自己也多少獲得了一點新知。上述討論從大數定律和共變或相關性的概念中得到了一些啟示。具體的內容留待下一章繼續講述。
小結
在考慮某件物體或事情時,應當時時將其當作整體中的樣本來加以考量。在某一特定情境下在某家特定餐館吃到的飯的質量,某一個運動員在某場比賽中的表現,我們待在倫敦的那一周的降雨情況,我們在派對上遇到的一個人到底有多好——這些都需要考慮到樣本在整體中的狀況。而我們在對所有這些變量進行評估時都或多或少犯了錯誤。在其他條件相同的情況下,樣本容量越大,就越可能讓一個錯誤被另一個錯誤消解,從而讓我們更接近總體的真分數。當某些事件很難用一個數字來評斷時,就像許多可以很容易通過編碼來評斷的事件一樣,那麼此時大數定律就能夠發揮效用了。
基本歸因謬誤主要是由我們忽視情境因素的傾向而導致的,但是我們「忽視掉一個人只是組成人類行為的一個微小樣本」這件事也是導致錯誤的原因。這兩個錯誤引發了訪談錯覺——我們總是對自己過度自信,相信從某個人30分鐘的言行裡就能瞭解他。
只有當樣本不存在偏差的時候,增加樣本容量才能有效減少錯誤。最佳方式是給總體中的每一件物品、每件事或每個人同等的機會被選為樣本。至少我們得重視樣本偏差出現的概率:在卓希皮亞公司時,我和簡相處得輕鬆愉快,還是說因為她的挑剔我總感到緊張?如果本就有偏見存在的話,更大的樣本量會讓我們對自己的錯誤估計更有信心。
標準差是一個便捷的可用於我們衡量連續變量在均值附近離散情況的指標。某個給定類型的樣本的標準差越大,我們越無法確定一個特定樣本值能否接近樣本均值。某一種投資類型若有較大的標準差,則意味著它未來價值變化的不確定性會更大。
如果我們知道某個樣本值位於連續變量正態分佈曲線中的極端位置,則新出現的樣本值將會不那麼極端。一個在上次考試中獲得最高分的學生可能下次考試也確實發揮得不錯,但他不太可能再次拿到最高分。去年某個領域的10只表現最佳的股票在今年不可能蟬聯十佳。極端分數或其他一些極端值的出現是因為它們在當時的情境下恰好吉星高照(或霉運當頭)。這些幸運符下次可不會在同樣的位置出現的。