本章前面部分探討過給現有比特幣所有者配置新的另類幣的兩種方法:或者要求用戶把比特幣銷毀從而得到另類幣,或者簡單地把另類幣發給現有比特幣所有者,這些所有者必須擁有還沒有用掉的比特幣。正如我們看到的,任何一種方式都不需要另類幣的價格盯住比特幣。沒有這種匯率鎖定機制,在發展初期,另類幣的價格會變化很大。側鏈(sidechains)的目的就是避免另類幣價格變化太大,因為價格的波動太大會導致很多問題,也會使另類幣分心乏術,無法真正專注於技術上的競爭。
下面介紹使另類幣的價格以固定匯率的形式盯住比特幣的相關技術。首先,所有者必須把所擁有的一定數量的比特幣放入托管賬戶,這樣才能創造出一個單位的另類幣(或者固定單位的另類幣),這樣所有者才可以在另類幣區塊鏈上正常使用另類幣。最後,所有者必須能夠銷毀自己擁有的另類幣,從而取回之前存在托管賬戶上的比特幣。這種構建像零幣,通過托管基礎幣而創造零幣。區別在於,需要在兩個不同的區塊鏈裡進行上述操作。
遺憾的是,據我們瞭解,由於比特幣的交易無法被其他區塊鏈的事件所影響,目前還未找到可以不改動比特幣而達到這種效果的方法。截至目前,比特幣的腳本還沒有強大到可以確認整個單獨的區塊鏈。好消息是,我們可以通過相對實用一點的軟分叉來修改比特幣,這也是側鏈的原理。側鏈的願景是,將比特幣作為儲備貨幣,打造多種蓬勃發展、快速創新和實驗的另類幣。截至2015年,側鏈還只是一個提案。但是比特幣社區正在積極參與這個提案,目前已取得一些實質性的進展。側鏈的提案還處於變化之中,所以為了便於學習和理解,我們適當簡化了一些細節。
擴展比特幣的功能,使之能夠使側鏈兌換成比特幣,最顯而易見但不太實用的辦法是:把所有側鏈的規則,包括驗證所有側鏈的交易和檢查側鏈的工作量證明,都包含在比特幣體系裡。這個方法不實用是因為這樣會使比特幣擴展出來的程序過於複雜,驗證比特幣的節點會非常困難。而且,鏈接上的側鏈越多,複雜度和困難度就越大。
SPV技巧
可以使用SPV證明技巧來避免這種複雜局面。在第3章中,我們曾提到簡單付款驗證(Simple Payment Verification,簡稱SPV)。SPV可用於小的客戶端,比如手機上的比特幣應用程序(APP)。SPV節點不需要對其不感興趣的交易做驗證,它們只校驗區塊的標題。SPV客戶只看他們感興趣的交易,並確信是在最長的區塊鏈內,並不擔心該鏈是否是最長的有效鏈。因為他們假定礦工在創建該區塊鏈並花精力去挖礦之前,已經驗證過裡面的交易了。
也許,可以擴展比特幣的腳本讓它能驗證側鏈裡某些特殊的交易(比如銷毀一個側鏈幣的交易)。在比特幣裡使用這種延展命令的節點,仍然會全面驗證比特幣的區塊鏈,但是在側鏈裡,可能只會驗證相對輕量級的SPV。
對一個交易提出異議
這種方法要好一些,但仍不完美。即使做最簡化的驗證,比特幣的節點仍然要鏈接到側鏈的點對點網絡(每個鏈接上比特幣的側鏈都需要如此),並且追蹤所有側鏈區塊的標題用於決定側鏈最長的分支。最終我們想要的是:當一個交易要把側鏈的貨幣轉化成為比特幣時,它本身就包含比特幣節點需要的用於驗證其合法性的所有信息,也就是說,驗證特定的側鏈是真實發生的。這就是SPV證明的定義。
這裡介紹一種可行的辦法,唯一的缺憾是這個側鏈的組成部分還在進一步研究中。為了在比特幣裡可以對照到側鏈,用戶必須證明:(1)側鏈區塊裡包含側鏈交易;(2)側鏈的標題表明這個區塊已經接受過一定次數的認證,這意味著一定數目的工作量證明。比特幣會驗證這些證明,但是不會去驗證這個區塊頭部展示的鏈是最長的。相反,比特幣會等一定的時間,比如1~2天,讓其他用戶去找證據證明,第二步所指向的區塊標題並不在最長分支上。一旦在特定時間範圍內出現這樣的證據,比特幣體系中,接受該側鏈交易的區塊將會被認定為無效。
隱含的邏輯是:如果一個SPV證明已經可以確定,該交易不在最長分支上致使其不應該被認可,那麼應該有一些側鏈的用戶會因認可這個交易而遭受損失。這些可能遭受損失的用戶,有動力去辯駁SPV證明。如果沒有用戶遭受損失(也許是有一個分支,或者重組側鏈,而且該交易也恰好在別的分支上),那接受這個證明也無妨。
一般來說,系統這樣設計,對側鏈問題並非毫無漏洞,系統也不會阻止你自己搬石頭砸自己的腳。如果你把比特幣轉成有加密隱患的側鏈,其他人也許能偷走你的側鏈幣然後再轉成比特幣。或者,在側鏈的挖礦,也許會因為側鏈漏洞而全部崩潰,導致對應的比特幣也被偷。但是可以肯定的是,側鏈的問題不會毀掉比特幣;具體地說,不管側鏈有多少漏洞,所有者都無法在側鏈上兌現兩次同一貨幣,也就是說側鏈不允許比特幣挖礦。
通過權益證明精簡SPV證明的案例
還有一個障礙需要跨越。有些側鏈生成區塊的速度很快,也許每幾秒鐘就能產生一個區塊。這種情況下,對比特幣節點來說,單單驗證SPV證明就已經負擔很重了。這時,可以用一個比較聰明的統計學方法,大幅減少對N個區塊的驗證,也就是大幅減少O(N)的認證次數。
原理如下:當驗證深藏在區塊鏈中的一個區塊,其實是在驗證每個建立在這個區塊上的所有的區塊都符合目標困難度(target difficulty), 即滿足哈希值<目標值。這些區塊的哈希值均勻地分佈在(0,目標值)的區域,從統計學角度看,這意味著大約25%的區塊可以滿足哈希值<目標值/4. 事實上,尋找N/4個區塊滿足哈希值<目標值/4的工作量和計算N個區塊滿足哈希值<目標值的工作量一樣。這個數字4並無特別,我們可以用任何數代替。
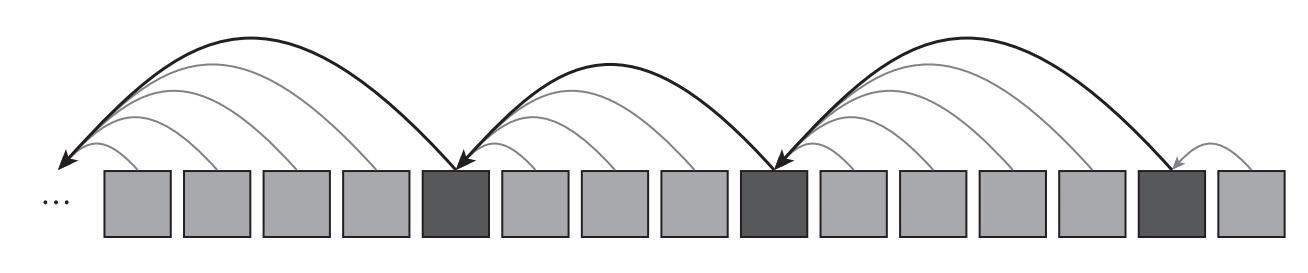
圖10.7 工作證明跳表(proof-of-work skip list)[1]
註:區塊包含指向前面一個區塊的指針和指向最近的滿足哈希值<目標/4的指針。這個原理可以重複運用,比如一個第三層級的指針指向滿足哈希值<目標值/16[2]
這就意味著如果找到某種方法可以知道哪些區塊滿足哈希值<目標值/4,僅驗證這些區塊(或者區塊的頭部)就可以使用1/4的工作量完成全部任務。如何找到哪些區塊滿足哈希值<目標值/4呢?其實答案在區塊本身。圖10.7顯示,每個區塊包含指向前面一個區塊的指針,以及指向最近的滿足哈希值<目標/4的指針。
可以壓低目標值到多小?是否可以選擇很大的數,讓目標值變得非常小?答案是否定的。這種方式的原理就像礦池,卻是反方向的操作。在礦池裡,礦池管理員驗證大家的份額,也就是驗證這些難度係數低(比較高的目標值)的區塊。礦工找到比區塊更多的份額,所以礦池管理員必須多做一道驗證程序的工作。這樣做的好處就是,能夠比較精準地估計礦工的哈希算力——估計值的方差較小。
我們來看相反的交易。隨著估算建造整個區塊鏈的工作的減少,估算值就有很大的方差。例如,假設N=4,在沒有使用跳表的方案下,會檢測到有4個區塊滿足哈希值<目標值。如果一個惡意的競爭對手要欺騙我們,他需要花4倍於我們找到一個區塊的平均工作量才能辦到。
假設這個競爭對手只做了一半的工作。可以算出,競爭對手有14%的機會能找到4個區塊滿足哈希值<目標值。相反,在跳表方案下用4作為倍數,競爭對手的任務變成需要找到一個區塊,滿足哈希值<目標值/4。在這種情況下,懶惰的只做了一半工作的競爭對手,卻有40%的機會騙過我們,而不僅僅是14%。
[1] 跳表是一種隨機化的數據結構,目前開源軟件Redis和LevelDB都有用到它。——譯者注
[2] 16是2的1+3次方。——譯者注,以此類推。